本笔记内容来自卓克讲座及讨论内容。
比特币的目
比特币的目的是生成一个任何人都不能更改的账本,这个账本在分布式系统中的每一个结点都保存一份,并且同步更新。账本可以是一条交易记录,比如:我向李三转账100个比特币。这个动作,在相应的软件上会做3件事:
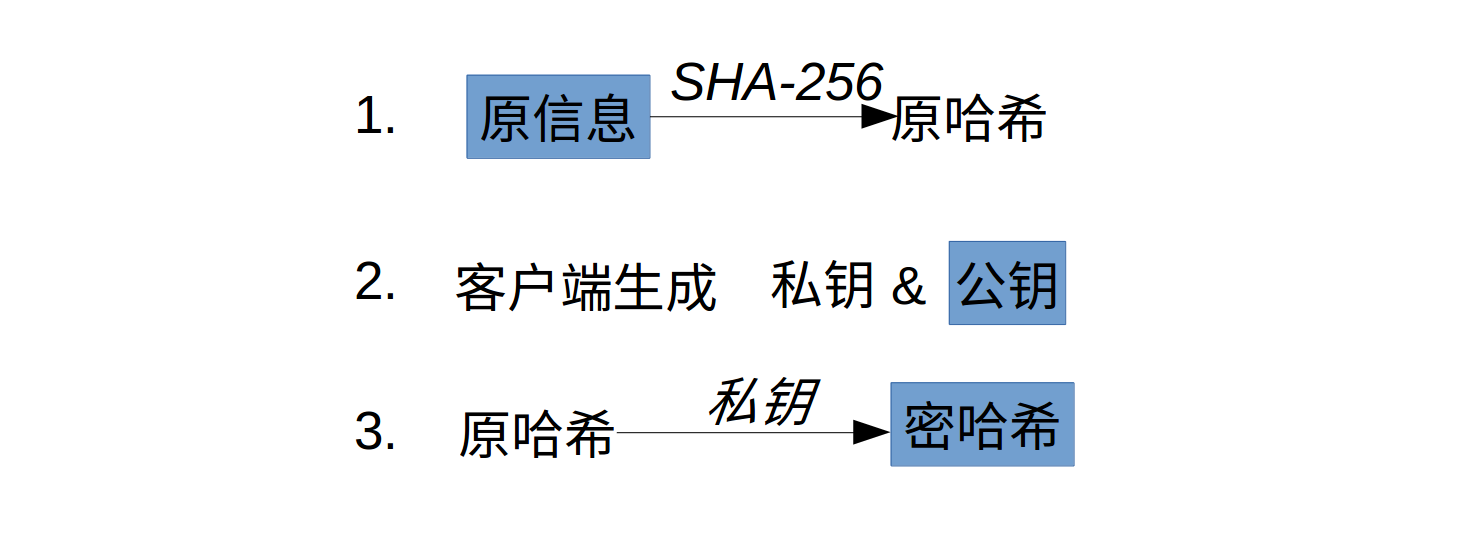
- 将“我向李三转账100个比特币”作为
原始信息,对其做一次SHA-256运算,得到的结果是一个原哈希值。
- 用我自己的私钥给上一个结果(原哈希值)加密,得到加密后的
密哈希。
- 将
原始信息,公钥(我自己的私钥对应的公钥),密哈希,3项内容广播到网络中。
之后图中三个矩形框的内容就被广播到网络中。
对任何内容进行SHA-256运算都能生成唯一的256bit的二进制数,没有办法从这个二进制数推出原始信息,所以SHA-256函数特别用于对比两条信息是否相同。比如我完成向李三转账100个比特币之后,别人就可以对纸条交易信息用SHA-256函数进行验证,如果结果与我给出的原哈希值相同,则表示这条信息是没哟被篡改过的。
使用公钥私钥的方式是非对称加密,那么对称加密有什么不好呢。
对称加密
加入我要向李三发一条信息:315,对他加密,方法是每一位加2,得到加密后的信息537,537在网络中传播,到达李三后,用我俩约定的加密解密方式只需要每一位减2,得到原始信息315。此过程中的“2”称为对称钥匙。
对称钥匙的缺点是,我不论是以什么样的方式告知李三,钥匙最少需要一次的传递。这个传递过程可以被监听。所以有了非对称加密技术。
非对称加密
1978年新的加密技术出现了。加密解密使用不同的两把钥匙,使用其中任何一个加密,那么另一个就可用来解密。非对称加密技术是通过一种很巧妙的且不可逆的数学运算的,成对存在。两把钥匙中,一把永远保留在自己手中,且只有自己知道,这个叫私钥,另一个公开给他人的称为公钥。
公钥私钥-加密&签名
私钥公钥有两个功能:
- 加密信息。当他人要给我发送加密消息,只要查询我的公钥,用公钥加密后发给我,我收到后送我的私钥解密,就可以获取原消息。整个过程没有任何钥匙的传递。所以这种方式由很强的安全性。
- 签名。此时对钥匙的使用是反着来的。当我要想他人证明这条消息确实是我发出的,我需要先使用私钥加密,后将加密后的信息广播出去,他人使用我的公钥解开就可以了。若解开了,则证明该信息是由我发出。
回顾一下,SHA-256函数的作用是为了确认原文是否被修改过,公钥私钥是用来确认交易信息签名的。到此,这个交易的加密信息和公钥就被传播出去了。
那交易记录为什么要被加密呢?如果没有加密,那么同一条消息可以由任何人写出,如何判断对比哪一个才是我的呢,由我授权的呢。所以需要私钥加密,后别人用公钥解密判断是否是我授权的。经过这一过程,这个交易(区块)就有可能成为链上的新区块。注意是“有可能成为”。
区块
矿工验证若干条交易信息,按照一定格式打包后,得到的称作区块。一个区块包括头部和交易部分。
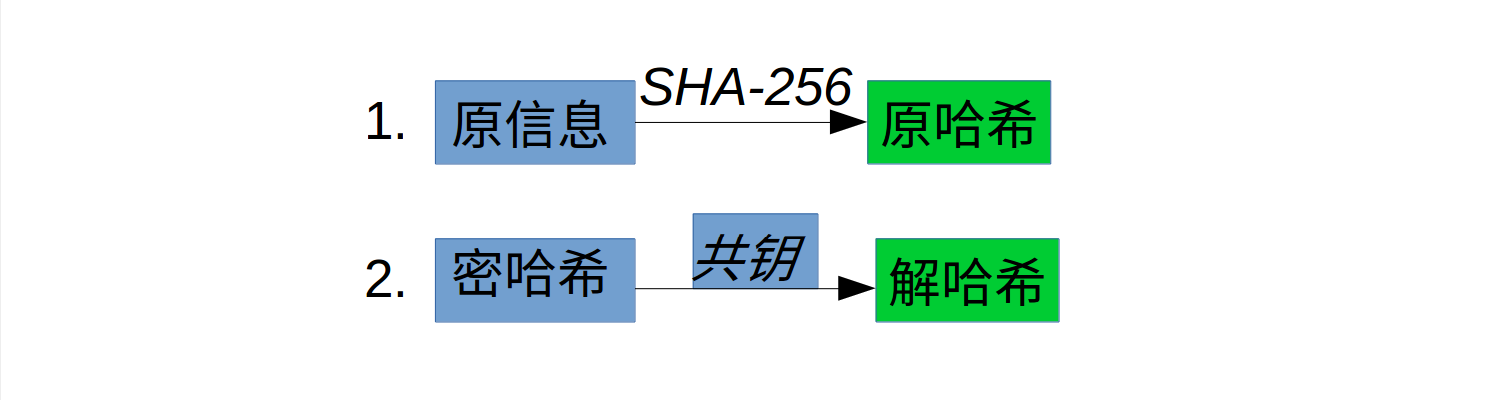
矿工做验证
交易的加密信息和公钥就被传播出去了之后,需要验证,这些人使用客户端软件验证,他们被称为矿工。当矿工从网络中获得我广播的3条信息后,矿工根据其做下面两件事:
如果原哈希==解哈希,表示这个区块的信息没有被篡改,是经过我签名的。到此,这个交易就有可能成为区块链上的新区块。
矿工验证的过程是竞争让自己打包的交易信息成为区块挂在区块链的结尾。为什么这里需要竞争?【物理位置不同,搜索到的交易信息也不同】全世界的矿工即使都打包好了自己的区块,相互区块之间的差别是很大的,那哪一个才有资格称为幸运儿呢,这需要一项额外的(无意义的)工作来证明:工作量证明。
这里猜测一下,添加到链上的区块不是关注其原始交易是什么,而是看这个区块的前若干位是否都是零。其实互不相干的多条交易信息相对于同一个时间是无序的,所以两条不同交易信息谁在前谁在后,对于区块链没有关系,反正所有历史信息都会被记录。所以添加区块的资格就需要工作量证明。
添加新区块的资格
工作量证明:将打包的区块看做一个字符串,在其末尾添加一个随机数,最后对这个字符串执行SHA-256操作,已经知道SHA-256操作的结果是一个长度为256的二进制数。谁先计算出的结果中的前72位都是零,那么谁就有资格将自己的区块添加到链尾。成功提交这个区块的人,系统会奖励其若干个比特币,这个奖励是逐渐减半的,等差数列计算一下就知道,总的比特币数量为2100万个。
最长链,主链
比特币协议中只承认最长链,所以如果在某个结点出现了分支,那么哪一个分支最先出现下一个区块,表示这个支链就会更长,它将作为从此之后的主链,而另一个分支的交易会作为无效,比特币退回。
有了这个规则,即使一个区块被人篡改,对主链也不会有影响。因为所有算力都在主链上,那个被篡改的支链,只能确保自己的推进速度超过主链的推进速度,才有可能在未来某个时间成为新的主链,但显然一个人的算力对抗其他所有算力,是赢不了的。所以,篡改无效。
当前区块包含了全部交易历史信息的特
一个区块包含两部分,头部和交易信息,其中头部包括上一个区块的信息,具体是上一个区块的SHA-256函数值。如此递归,容易知道,链中的每一个区块都含有其上一个区块的信息。所以说任何一个区块都含有这个区块之前整条链的所有信息。
比特币有很多问题
根据上述描述,可以发现比特币的问题:
- 竞争获得添加新块的资格是靠算力裁决(工作量证明)的,而这个计算简单且没有实际意义的,损耗硬件算力和电能。
- 这个网络的交易频率太低,只有7笔交易每秒钟,VISA可以每秒钟处理千笔交易。比特币作为交易的属性太不明显。
- 区块链是在一个分布式系统中构建的,但是整个链都需要完整复制到每一个结点,并保持同步,所以存储,带宽成了大问题。其实这个系统的性能是由系统中性能最差的结点决定。
- 比特币意义不大,只是因为它是第一个出现的相关概念,外加大众的炒币,使其价格高,却极不稳定。
区块链诞生
行业黑话,给交易打包,叫块,将块连接成链。两者结合实现支付和账本功能,叫区块链。(这个区块链上流通的货币是比特币)
以太坊
对比特币改进的虚拟币由很多种,其中技术改进最大的是以太坊。以太坊中实现了许多比特币中没有的特性和功能。
以太坊vs比特币
主要有两点不同:
- 以太坊有两种账户:普通账户和合约账户。普通账户可以主动发起交易;合约账户不能主动发起交易,但是可以回应普通账户执行交易。比特币系统中保存的是不可更改的交易历史,而以太坊中除了不可更改的历史交易,还有一些不可更改的执行程序。
- 比特币是采用工作量证明来裁决,而以太坊是采用权益证明裁决。就是谁拥有的虚拟币多,谁打包成块后提交的成功率高。
以太坊对应的区块链被称为“智能合约”,不可更改,分布式存储,等待执行。其实并不智能,智能是可以自动选择最优方案的。
DAO案件
以太坊对应的区块链上哪个时候有漏洞,如果要打补丁,会重新产生一条新的主链,这是个大改动,而且碰到漏洞的概率很小。所以没有及时打补丁。直到黑客动手,偷走了5%的以太坊,价值5000万美元。又因为区块链是一个分布式系统(去中心系统,像最常接触的操作系统,都是中心化的,有漏洞,打补丁后重新发布新的版本就好),偷盗行为不能被禁止。幸好代码中有一条“28天后才能提现”的规定,最终90%的人同意将被盗后的主链设为无效,但10%的人由于在事件发生后合法地赚到了钱,而反对。所以之后以太坊被分为ETH和ETC两种,两个主链。
没有绝对安全的系统。
区块链的缺点
- 虽是分布式,但算力没有提升。一般的分布式系统是为了提高计算效率,而区块链的分布式系统,并没有增加计算效率。
- 存储低效。上万个结点要长时间保持同步,每个结点存储完整的区块链。
所以从计算机科学的角度讲,区块链设计精妙,但效率地,浪费资源的缺点是注定的。
区块链的应用落地太困难
一个应用是支付宝的“相互宝”,使用了区块链的技术,但民众真正使用它更多的是因为对支付宝的品牌信任。想象一下,如果不是支付宝,而是一个不知名的公司,大众还会考虑吗。
另外的应用是虚拟币交易所。
从无到有的创新在区块链上太难了。其中一个原因就是,创造区块链历史的都是一些挑战既有秩序的人,而这个级别的创新在中国不太可能出现。
中国的创新是对现有技术的延伸
回顾中国的互联网发展,正是通过中国的工程师在已有的技术上延伸而发展来的。一旦区块链技术在一个应用领域落地,在中国普及起来将会是很快的。