接文本预处理(一),这篇笔记记录把分词后的记录编码为计算机可识别的数值型序列,如将[你好 呀 , 参加 比赛 了 吗]编码为[91, 57, 1, 31, 14, 6, 5]。同时编码类别。
词编码
在上一篇笔记中得到的vocab_file,再看一下其内容:
1 | 1 <UNK> 10000000 |
每个词与其编号一一对应,可以用词的标号来对词进行编码。这就是下面主要做的事。
1. 一一对应
首先读取vocab_file,得到每个词,其编号,其频数,以{词:编号}为元素存入一个字典。同时指定一个整数threshold,当一个词的词频小于threshold,不再考虑该词,原因是频数太低的词没有统计意义。对每一条数据执行此操作,实现过程如下:
1 | def _read_dict(self, filename): |
最终得到目标dict:
1 | {'<UNK>': 0, ',': 1, '的': 2, '。': 3, '在': 4, '、': 5, '了': 6, '是': 7,...,'铭记': 20350, '多时': 20351, '轩然大波': 20352,...,'孵化器': 39545, '党史': 39546, '纸飞机': 39547,...} |
2. 编码
第二步,对于一个清洗后样本[你好 呀 , 参加 比赛 了 吗],从上一步得到的dict中找每一个key对应的value,从而生成[91, 57, 1, 31, 14, 6, 5]。实现过程:
1 | def sentence_to_id(self, sentence): |
现在用一个样本做测试:
1 | test_word = '你好 呀 , 参加 比赛 了 吗' |
返回实际结果:
1 | [9901, 5667, 1, 381, 124, 6, 445] |
同样的方法,处理label,如:
1 | 科技的id: 8 |
上述完整过程在这里
到此到此为止,所有的样本都已用数字编码。下一步为模型提供数据,batch by batch
3. 生成batch
首先读取清洗后的样本文件,对于每一条记录中的类别和内容按照上述方式编码,并分别存储与两个list。编码完一条记录,加入到list中。最终的到的内容list和类别list。
实现如下:
1 | with open(filename, 'r') as f: |
self._input中存储编码后的每一条内容,self._output中存储编码后的每一条对应的类别。特别说明,因为实际每条编码后的记录长度都不同,有的长,有的短。所以在代码中self._encoded_length表示每条记录保留多少个词。长的切去,短的用-1补全。
额外地对self._input和self._output做一个随机洗牌操作:
1 | p = np.random.permutation(len(self._input)) |
这个操作使每个batch中数据分布尽可能一致,尽可能可以代表整个数据集的分布。
第二步,生成batch。其过程如下图:
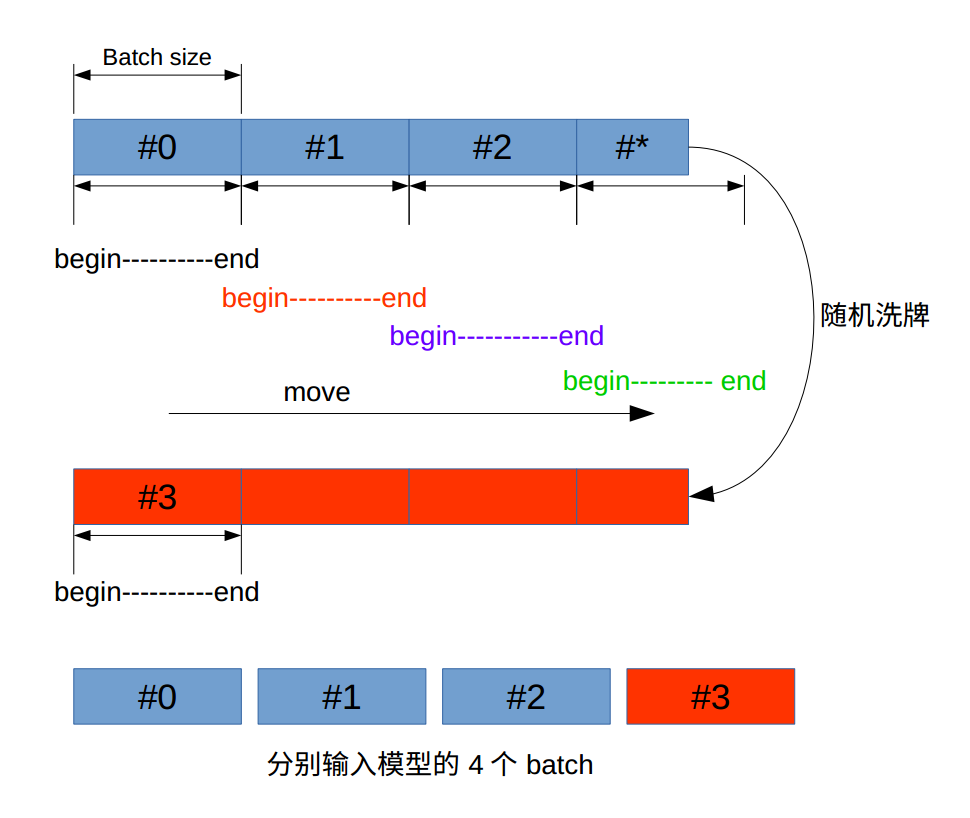
当图中最后的数据#*不足一个batch时,所有数据随机洗牌,这样就可以再得到一个batch。当然最后一个batch中有部分重复使用,这没关系。 代码实现如下:
1 | def next_batch(self, batch_size): |
测试:当_encoded_length为50,batch_size为2时,可能输出如下:
1 | (array([[ 5639, 5529, 28692, 14277, 108, 0, 825, 87, 7763, |
两条记录,第一条记录的类别为1,另一条的类别为4。
整个过程完整代码看这里。数据准备完成,便可以用于训练模型了。