在上一篇笔记文本分类(三)-构建模型I-built-in-LSTM 中tensorflow中的LSTM相关函数实现了LSTM层。这篇笔记记录把LSTM单元拆解,一步一步实现,即 from scratch
理解这一篇笔记的细节,要结合上一篇笔记,尤其是其最后一段,结合这里的细节,体会。
LSTM结点如下图:
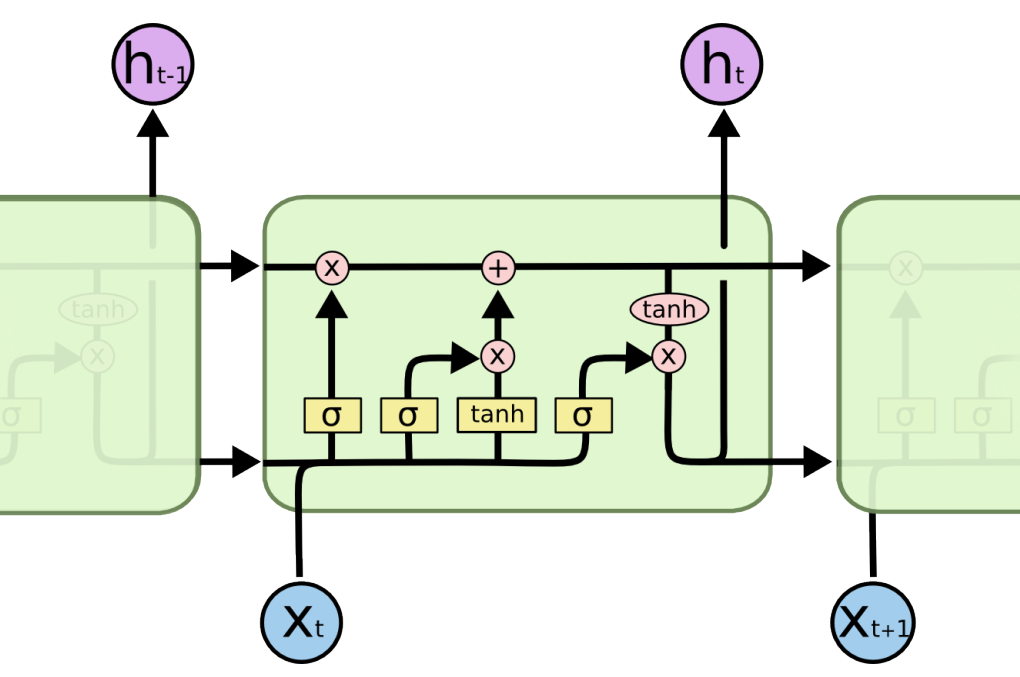
图:单个LSTM结点内部结构
一般RNN存在信息过载而不能长久传播的问题,LSTM单元结构存在三重门机制尝试解决这个问题。
假如一个词的编号为12,将它对应的embedding向量输入LSTM 结点中有一下过程发生:
- 得到这个词的embedding,大小为
[batch_size, 1, embedd_size]:
1 | embedd_input = embedded_inputs[:, 12, :] |
- 变形为:
[batch_size, embedd_size]
1 | embedd_input = tf.reshape(embedd_input, [batch_size, hps.num_embedding_size]) |
三重门过程,公式及实现:
遗忘门:
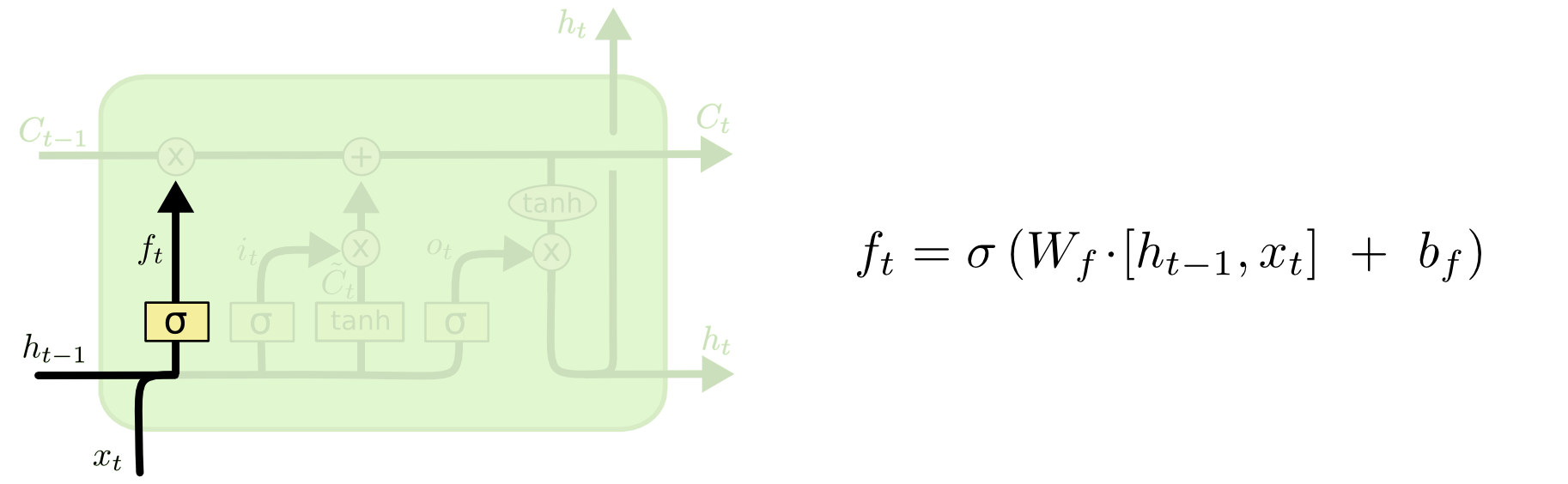
图:遗忘门
1 | forget_gate = tf.sigmoid( |
输入门:
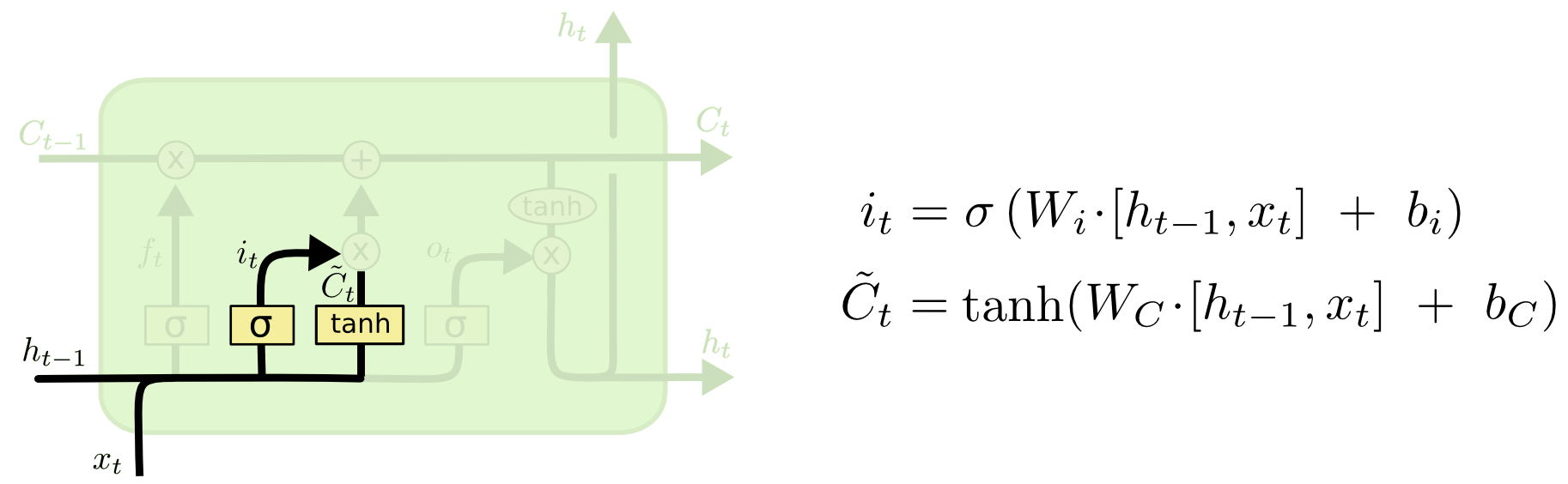
图:输入门
1 | input_gate = tf.sigmoid( |
结点隐含状态输出:
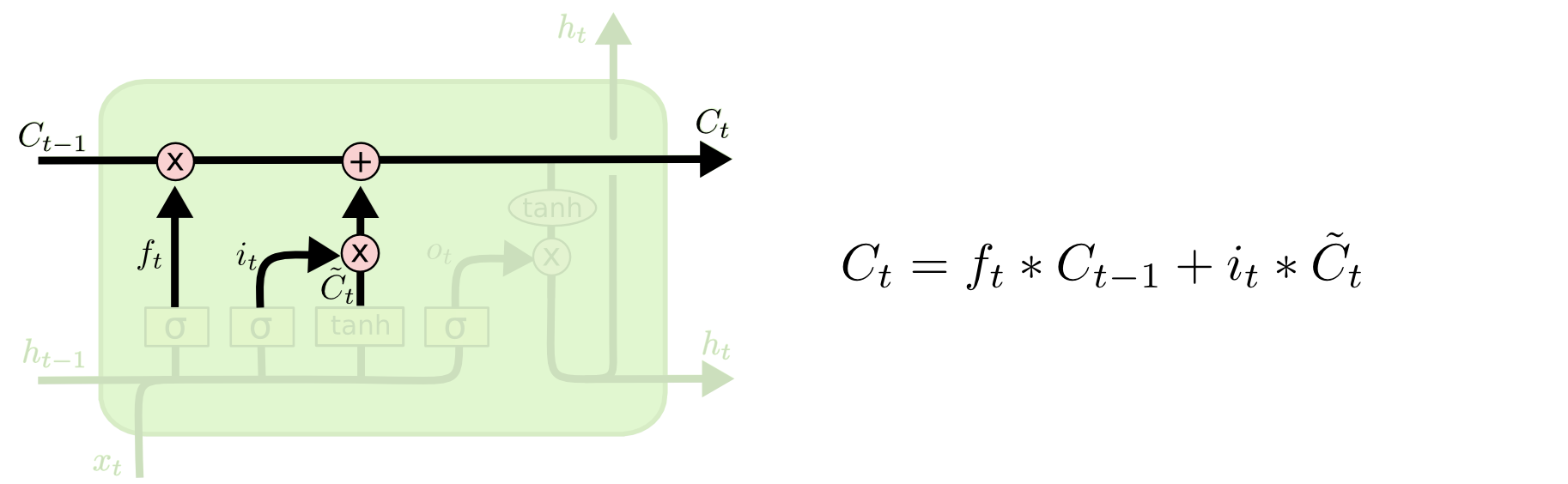
图:隐含状态
1 | state_C = mid_state * input_gate + state_C * forget_gate |
输出门及结点LSTM的输出:
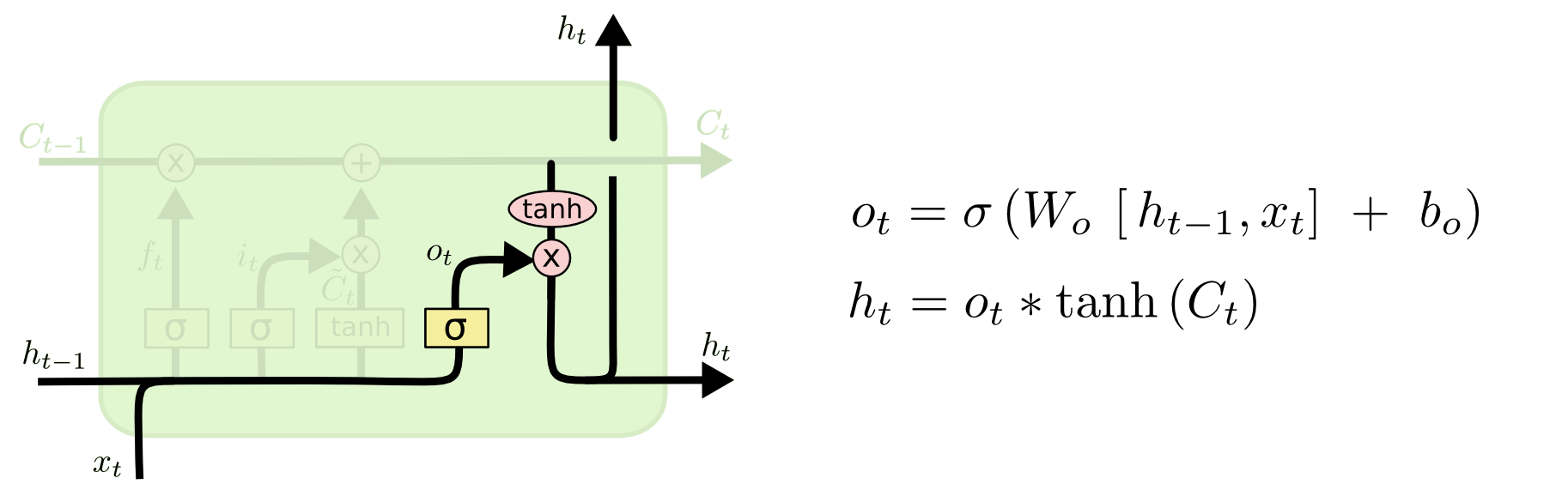
图:输出门
1 | output_gate = tf.sigmoid( |
以上是对于样本中一个词的操作,对于该样本中所有词的操作如下:
1 | for i in range(encoded_length): |
其中encode_lenght表示每一个样本(一条评论)的长度,即评论词的个数,此处是50个。
这个序列操作中有那两个值在不断更新
- state_C
- h
这两个值的不断更新使得对每个词操作的每个LSTM结点在逻辑上是连在一起的,如下图:
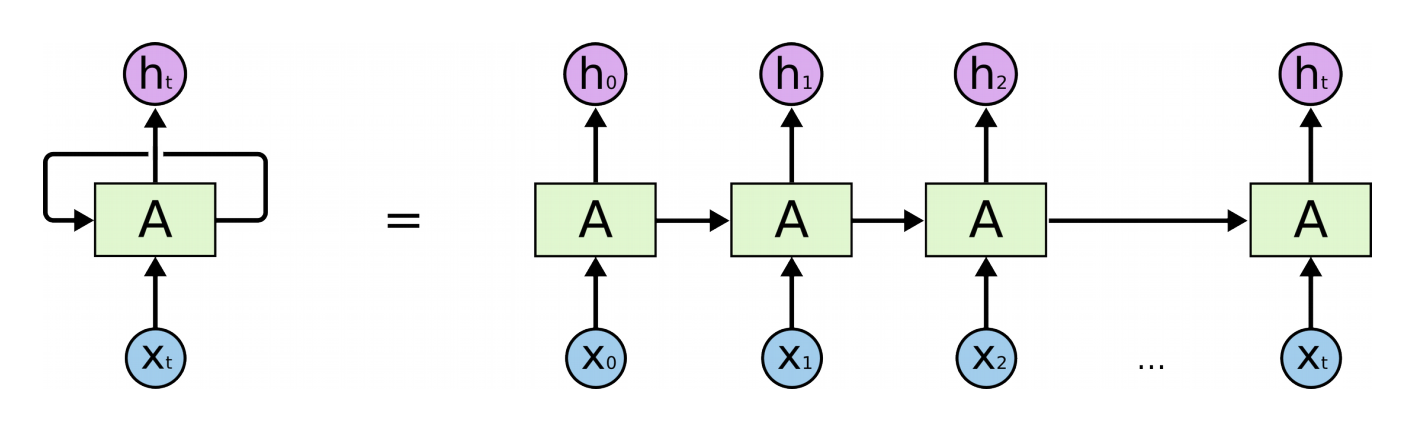
图:左侧是实际LSTM结点,右侧是这个结点从时间上展开后的
敲黑板将等号左边按时间次序展开就是右边。实现中一个LSTM结点可以代表一个神经元,只不过这一个神经元内部有5个非线性变换。对于复杂问题一个这样的神经元不足以表达输入数据,所以会有多个这样的神经元。
这里的实现源码看这里。源码中对网络的设置为:
1 | num_lstm_nodes=[32, 32], |
表示这个模型有2层LSTM,每一层的神经原结点有32个,而每一层中的每一个神经元所处理的输入序列长50!
务必理解
完成
LSTM结点实现。
本笔记所有图片来源与colah’s blog