杂记:
Loss Fucntion与训练
为啥会有Loss Function目标函数:如果要调整一个东西,让它符合一个事件的话,首先需要定义需要符合的事件是啥,这就是目标函数。也就是说,要基于什么样的目标来调整这个东西(模型)。
常使用的目标函数:
- 平方差损失函数。样本标签值与预测值的距离之和
- 交叉熵损失函数。衡量两个分布间的差距
训练目的:调整参数,使得模型在训练集上的损失函数值最小。
如何训练:直接解方程?不得行。所以有了以GD为代表的学习算法。
使用
Mini-batch梯度下降。如果每一次都在整个数据集上计算梯度,计算量巨大,可能内存不够。如果使用随机梯度(SGD)下降,即每使用一个样本就计算一次梯度,在一个样本上得到的梯度不能反应整个数据集的梯度方向,所以收敛速度慢。所以一般使用Mini-batch梯度下降。上述三种梯度下降法都存在一个缺点:会陷入局部最小值和鞍点。可以使用动量梯度下降(
SGD+Momentum)。其特点是,如果当前步的方向与上一步的方向呈锐角,实际方向在二者之间,且步长较大,若是钝角,则步长小。也就是说:- 刚开始积累动量,加速学习。
- 局部震荡时,梯度为0,由于动量的存在,跳出局部最优。
- 梯度方向改变时,动量缓解震荡。
CNN
为啥有CNN。在传统的NN处理图像时,由于全连接,导致
计算量大
参数过多,使得过拟合
CNN灵感来与生物的视觉感受野,其特点是局部连接,每个神经元在图片上移动时,其卷积核参数不变(参数共享),而不同的神经元间的卷积核参数不同。相比较于全连接,参数量减少了很多。参数共享:一个卷积核提取一个特征。所以CNN解决上述两个问题:
局部连接
参数共享
一个卷积核3通道分别与输入的3通道计算,得到的3通道计算结果相加作为输出的一个通道。如下图:
即一个卷积核得到一个输出通道,所以n个卷积核得到n个输出通道。
一个卷积核提取一个特征,所以6个卷积核提取6个特征。
其中
28 =(32-5)/1+1,即输出长=(输入长-卷积核长)/stride步长+1(步长为1)。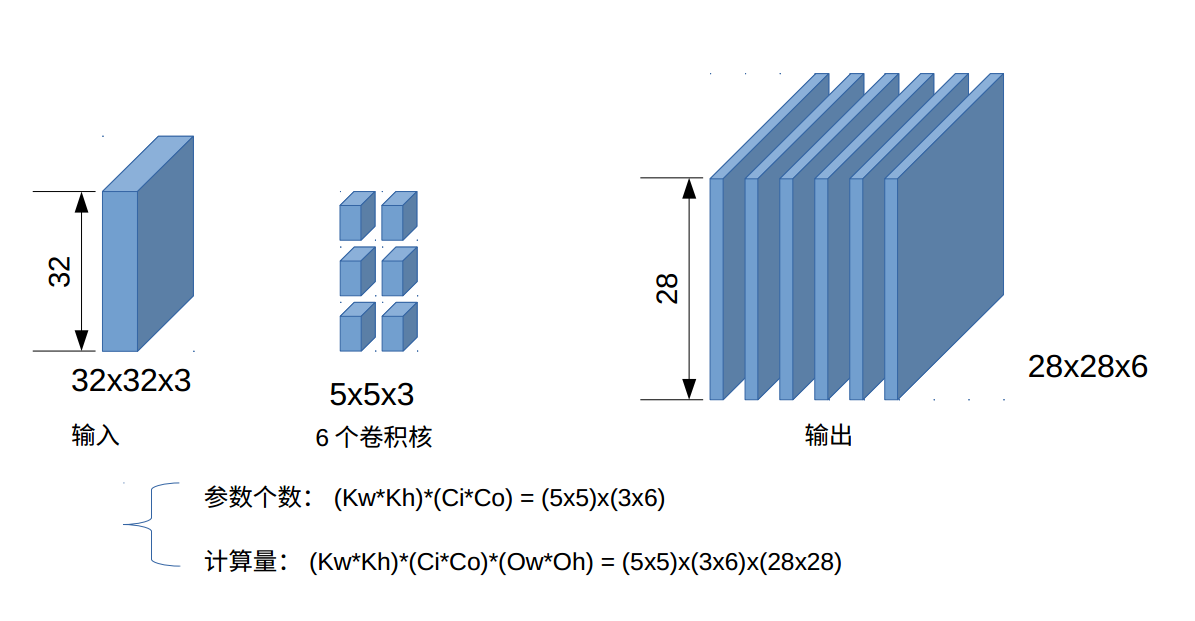
注意图中的参数个数和计算量的计算与输入尺寸无关。参数计算=(核长×核宽)×(输入通道数×输出通道数)。与图中一致。
激活函数选择(添加图示)
- 线性激活函数,对于网络无效,因为是全等变换,无论网络由多少层,都相当于只有一层。我们说激活函数的作用是非线性变换,而现行变换无效果。
- 深层网络不适用
sigmoid,因其计算复杂,输出均值非0,且会发生梯度消失,即更深的层参数得不到更新。 tanh虽然输出均值为0,但计算复杂,有和sigmoid相同的问题。ReLU首次在AlexNet中使用,计算简单,但输出均值非0,会存在dead 神经元。Leaky ReLU解决了ReLU的dead 神经源问题。ELU输出均值接近于0,MaxOut是ReLU的泛华版本,没有dead神经元,但参数会翻倍。
总结:一般使用Leaky ReLU,ELU,MaxOut。
Pooling
max-pooling,average-pooling, 特点:
- 池化核移动不重叠,
- 不补零,
- 无可训练过参数,
- 作用:降采样,为下一层减少尺寸,减少计算量,减少训练参数,
- 平移鲁棒性
全连接层FC
将上一层输出展开并连接到每一个神经元上。2D变1D,没有了2D信息,所以不能再加卷基层。实际上就是普通的NN。全连接层的参数很多,一般占整个模型参数量的60%~80%。
优化算法
SGD:
1
2
3while true:
dx = compute_gradient(x)
x += lr * dx动量SGD,解决鞍点和局部最优值,问题,每个维度的学习速率都一样:
1
2
3
4
5Vx = 0
while true:
dx = compute_gradient(x)
Vx = rho * Vx + dx
x += lr * VxAdaBrad:
1
2
3
4
5grad_squared = 0
while true:
dx = compute_gradient(x)
grad_sqaured += dx * dx # 积累平方梯度
x -= lr * dx / (np.sqrt(grad_sqaured)+1e-7)缺点:当learning rate较大时,分母敏感,使梯度爆炸。后期分母变大,使更新变得很小,提前结束训练。
RMSProp:
1
2
3
4
5grad_squared = 0
while true:
dx = compute_gradient(x)
grad_sqaured = delay_rate * grad_sqaured + (1-delay_rate) * dx * dx # 平均平方梯度
x -= lr * dx / (np.sqrt(grad_sqaured)+1e-7)解决了后期训练提前结束的问题。
Adam:
结合了动量SGD和RMSProp优点
1
2
3
4
5
6
7
8
9
10
11frst_moment = 0
scnd_moment = 0
while true:
dx = compute_gradient(x)
frst_moment = beta1 * frst_moment + (1-beta1) * dx
scnd_moment = beta2 * scnd_moment + (1-beta2) * dx * dx
# 校准
frst_unbias = frst_moment/(1-beta1**t)
scnd_unbias = scnd_moment/(1-beta2**t)
x -= lr * frst_unbias / (np.sqrt(scnd_unbias)+1e-7)使得开始训练时frst_moment和scnd_moment变大来加速训练。一般使用Adam算法,从经验来讲,beta1=0.9, beta2=0.999,lr=1e-3。
lr自适应方法:
1
2
3
4# Exponetial Decay:
lr = lr * e**(-kt)
# 1/t Decay:
lr = lr / (1+kt)SGD训练时间长但效果好,不过需要好的初始化,和lr自适应,如果不能找到好的初始化和lr自适应,用Adam。如果要训练更深更复杂的网络,且要求收敛速度快,推荐使用Adam。
网络需要初始化 (添加图示)
好的初始化使训练速度快,且达到一个好的结果。多层网络不适用0来初始化。
如何判断初始化的好坏?查看初始化后各层的激活函数的分布,如果分布在一个区间内,好;如果输出集中在某个值上,不好。
一般使用均值为0方差为0.02的正态分布来初始化。
对于tanh使用Xavior初始化:
1 | w = np.random.rand(channel_in, channel_out)/np.sqrt(channel_in) |
对于ReLU使用He-ReLU初始化:
1 | w = np.random.rand(channel_in, channel_out)/np.sqrt(channel_in/2) |
其网络每一层分布都相近。
批归一化
通用的归一化方法:
为了使得每层激活函数的分布一致,在得到激活函数值后,把输出做归一化处理:减去均值,除以方差,使得其值分布在均值为0,方差为1 的分分布上。
缺点:表示在每一批上做归一化,但是,一批的分布不能反应整个数据集的分布,结果是,得到一个特征,批归一化后,这个特征不能在批不批间区分样本了,即特征无效了。
解决:设置alpha&beta两个参数做逆归一化:
1 | 数学公式 填坑 |
数据增强
多尺度剪裁。
Fine-Tuning
在已经训练好的网络上进行微调。使用已经微调好的模型来初始化。见Fine-tuning博客。