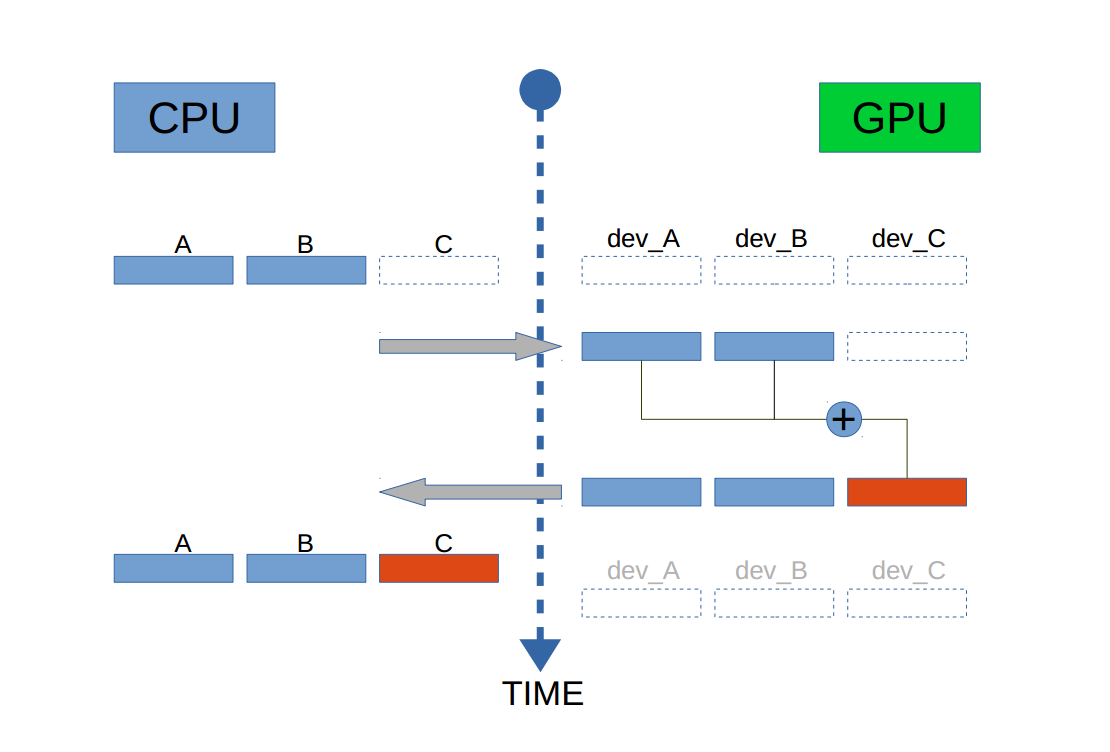
一个实例
检查环境:
nvcc -V:CUDA编译器是否安装nvidia-smi:显卡驱动是否安装
cuda代码文件以.cu结尾,当写好一个文件后,使用NVIDIA 的编译器编译 nvcc FILE-NAME.cu,后./FILE-NAME执行。
从一个实例讲起:
两个向量相加,结果存入另一个向量。
代码如下:
1 |
|
上述代码包含了CUDA代码的一般步骤:
1)声明所需指针在GPU,并且在GPU上开辟空间, 使用函数
cudaMalloc()2)从CPU拷贝所需内容到GPU的内存中,使用函数
cudaMemcpy()3)配置核函数,并执行操作。该函数在main函数之外,以
__global__开头4)把GPU上计算得到的结果拷贝回RAM,使用函数
cudaMemcpy()5)释放VRAM中的空间
从两个维度理解CUDA基本概念- 物理层
- 逻辑层
物理概念
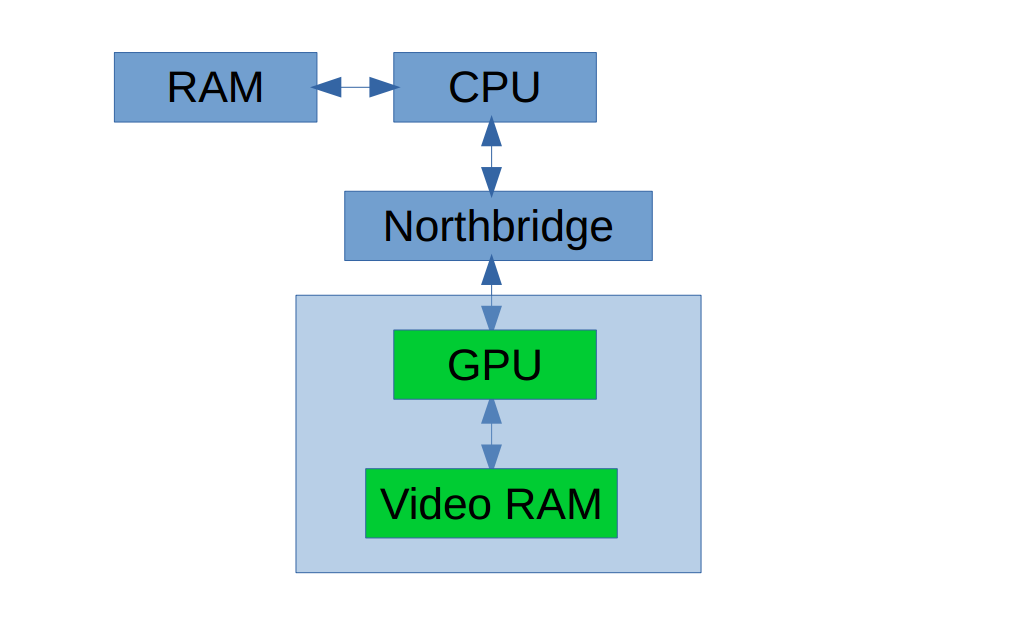
CUDA中的两个对象:Host,Device
- Host 包括 CPU 和内存 DRAM
- Device 包括 GPU 和存在与其上的存储 VRAM
VRAM 是 off-chip memory,即不在芯片上。由三部分组成:Global Memory,Texture Memory 和 Constant Memory。其中后二者为 read-only。
GPU 芯片上的 memory 包括 Registers,L1-cache, L2-cache 和 Shared Memory。
每个 GPU 芯片拥有一组不同的 memory,如上述。其中最重要的两个是 Global Memory 和 Shared Memory。
Global Memory 类似CPU系统的 RAM,Shared Memory 相当于CPU的片内缓存。
Host 和 Device 由北桥芯片连接:
对于CUDA编程,你需要负责以下内容:
1) 在 GPU memory 上开辟空间
2) 拷贝数据从CPU上到GPU上
3) 在GPU上执行 kernel 代码
4) 再把结果从GPU上考回CPU
5) 协调Host 和 Device中的操作
使用GPU编程时,要从 MIMD(Multiple Instructions Multiple Data) 的思考形式转变到 SIMD(Single Instruction Multiple Data),在CUDA 中,每个核心执行的代码指令都是一样的,所以说是Single。
CUDA 提供的重要功能:组织线程,memory access。
与CUDA并行编程的代码分为两部分:
- Host 部分代码由 ANSI C 来完成
- Device 部分由 CUDA C 来完成,也对C++逐渐支持。
知道怎样组织 threads 在使用 CUDA 是十分重要的。
逻辑概念
在一个 grid 中所有的 thread 共享相同的 Global Memory。来自不同 block 的 threads 不能相互交流。即属于同一个 block 的 thread 可以相互交流。
- threadIdx.x: 每个 block 中 x 方向 thread 的 id
- threadIdx.y: 每个 block 中 y 方向 thread 的 id
- threadIdx.z: 每个 block 中 z 方向 thread 的 id
- blockIdx.x: 每个 block 的 x 方向上所含的 id
- blockIdx.y: 每个 block 的 y 方向上所含的 id
- blockIdx.z: 每个 block 的 z 方向上所含的 id
- blockDim.x: 每个 block 的 x 方向上所含的 thread 数
- blockDim.y: 每个 block 的 y 方向上所含的 thread 数
- blockDim.z: 每个 block 的 z 方向上所含的 thread 数
- gridDim.x: 每个 grid 的 x 方向上的 block 数
- gridDim.y: 每个 grid 的 y 方向上的 block 数
- gridDim.z: 每个 grid 的 z 方向上的 block 数
grids 和 blocks 使用 dim3 数据类型。 当给了数据的大小,如何决定 grid & block 的维度。
- 1)先决定 block 大小,即每个 block 由多少 threads,
- 2)然后根据数据大小和 block 大小,计算 grid dim。
为了得到 block dim,考虑两点:
- 1)kernel 的性能特点
- 2)GPU的物理极限
- 我的芯片的数据:
func<<<32, 1024>>>():
- 32:block 的数量为32个
- 1024:每一个 block 的 thread 数为1024个
为了配置 kernel 你需要知道:
- 1)kernel 的 thread 总数
- 2)这些 threads 的分布:block & grid 的维数,每个 block 由多少 threads
举例子:
假如我想使用32个threads,我想 配置一个1D grid 1D block kernel func<<<4, 8>>>(),其 thread 分布是:
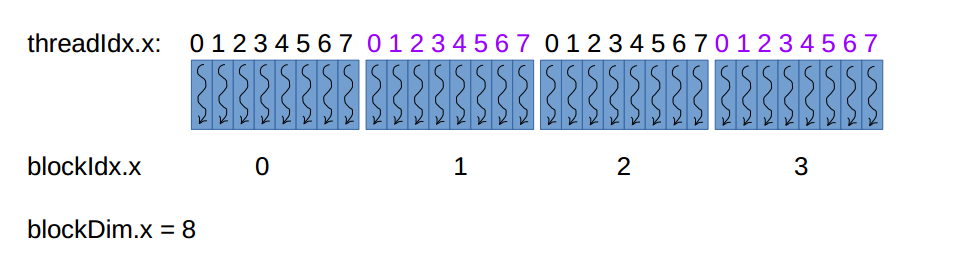
32个 threads 决定了会有32 份func()的拷贝,每一份由一个thread 执行,唯一不同的是每一个thread 的ID,这样计算:idx=threadIdx.x + blockDim.x * blockIdx.x。
如第二个block的第一个thread 的ID是 0+8*1=8,最后一个thread的ID是7+8*3=31,所以,这个配置中的所有threads由唯一的ID:0~31。
再如:2D grid,2D block kernel:
1 | dim3 threads(2, 4) |
下图是所有相关的参数,及怎样得到每个 thread 的 ID:

更多kernel的配置:
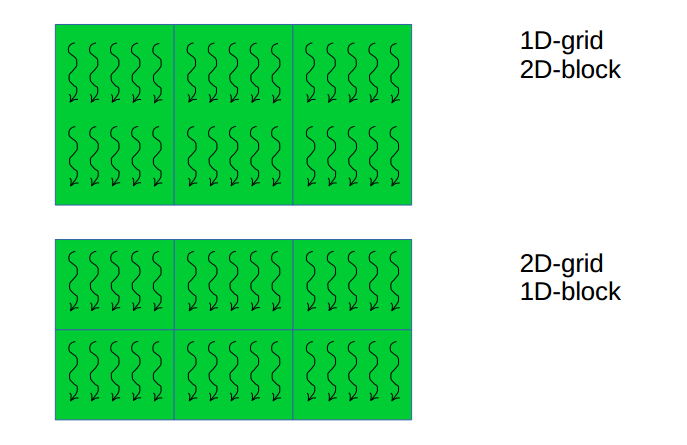
其中矩形表示一个block,相邻blocks组织成grid。
核心概念:
grid 由 block 组成,可以是1D,2D,和3D。
block 由 thread 组成,也可以是1D,2D,和3D。
根据具体问题,选择 block/grid 的维度。一般来说:
1D 适用于 vector 操作
2D 适用于 images
3D 适用于 3D space