- 决策树是非参数学习算法
- 天然解决多分类问题
- 有很好的可解释性
- 关键问题是使用哪个特征做为根节点
- 对于连续值的特征,在哪个值上做划分
离散数据集
使用iris数据集,调用sklearn的Decision Tree 模型:
1 | iris = datasets.load_iris() |
结果:
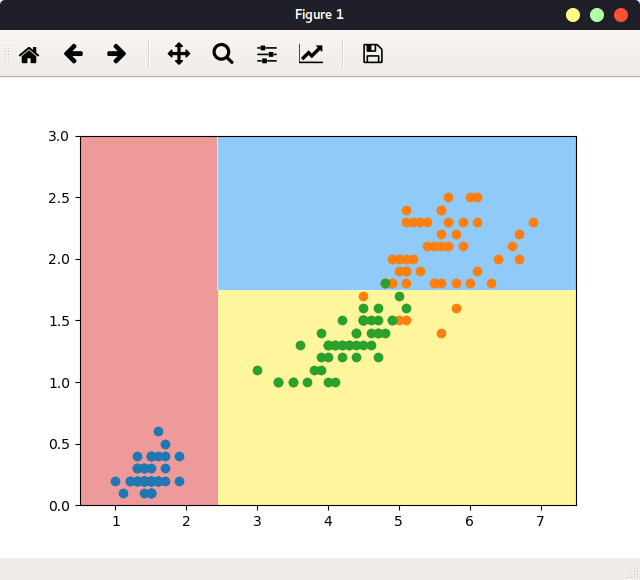
图 深度为2的决策树
划分后使得系统的熵(即不确定性)降低。所以对于一个划分,如果划分后的系统信息熵比其他划分后的熵都要小,则当前就是用这个划分。根据这个原理,可以就特征为连续值的数据集进行划分:
连续值的数据集
已知特征d,和value, 对x进行划分:
1 | def split(x, y, d, value): |
传入label列表,求此时的系统信息熵:
1 | from collections import Counter |
定义一次划分,即,划分算法:搜索找到使得熵最小的特征d和value:
1 | def try_split(x, y): |
调用函数得第一次划分:
1 | # 第一次划分: |
左子树的熵为0,右子树的熵大于0,所以对右子树进行第二次划分:
1 | # 对于右边再次划分: |
可以继续深入划分。
由于数据集各个特征值是连续的,所以,上述过程是:遍历找到所划分的特征,这个特征中遍历的所有样本,排序后求相邻两个样本的均值作为这个特征的具体划分值,时间复杂度为O(mxn),即样本个数乘以特征个数。
对于各个特征值为离散的,使用信息增益来找到消除不确定性最强的特征。每次都找信息增益最大的属性作为下一个划分属性。