之前说过,集成学习分为两类:学习器间无关系,和基学习器间有关系。前者常使用Bagging 和随机森林。而后者常使用Boosting。Boosting的工作机制如下:先从训练集中训练出一个基学习器,然后根据这个学习器的表现调整样本分布,使得先前的学习器分类错误的样本在后续收到更多关注,最后基于调整后的样本训练下一个学习器。如此反复。也就是说,每个基学习器都在尝试提升整体效果。可以看出,Boosting不能并行执行。
常见两个Boosting
- Ada Boosting
- Gradient Boosting
Ada Boosting
Boosting算法最著名的代表是AdaBoost:其过程如下:
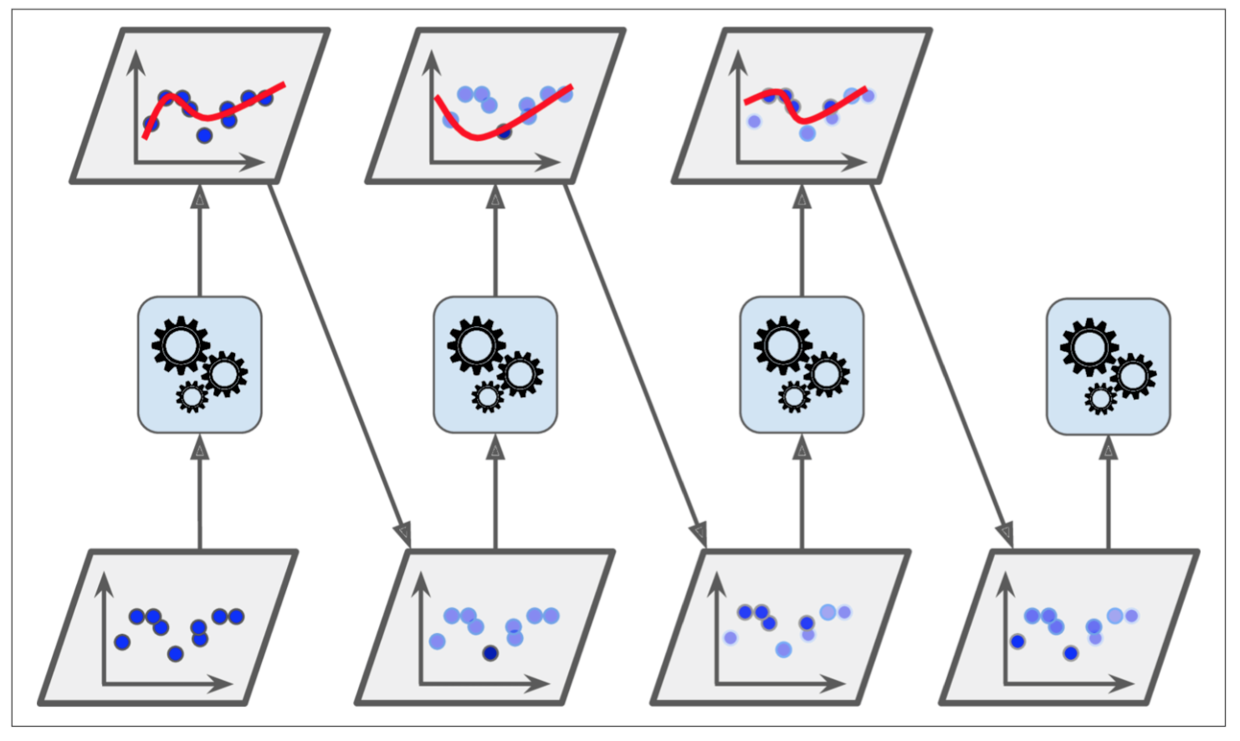
初始样本集每个样本有一个权值,当第一个学习器学习完后,对于不能正确捕捉的样本,调整这些样本的权值。然后第二个学习器接着学习,对于不能正确捕捉的样本调整权值。然后让第三个学习器接着学习。如此反复。可以看出,在整个样本的学习过程中,样本的权值在不断变化。
那么怎样给样本点附上权值,这其实是个问题转化,转化为求极值的问题。
sklearn中使用AdaBoostClassifier()实现:
1 | # 数据集 |
在测试集上结果:92.0%
Gradient Boosting
Gradient Boosting 是另外一种思路,它仅以决策树为基学习器。过程如下图:
对于所有样本,训练第一个模型m1,得到所有分类错误样本。对于上一步中的所有错误分类样本,训练第二个模型m2, 得到这次分类错误样本。如此反复。最终的模型m等于这个过程中所有模型之和:m = m1 + m2 + m3 + m4 + ...。
sklearn使用GradientBoostingClassifier()实现:
1 | # 同样的数据集 |
模型在测试集上的性能: 88.0%
Gradient Boosting 其实是一种残差学习,每一个学习器并不是学习整个样本集,只学习错误分类集。
同样的,Ada Boosting 和 Gradient Boosting 也可以用来处理回归任务。