- 作用是优化一个目标函数,它是一个基于搜索的数值优化算法。具体说来,当需要最小化一个损失函数,使用梯度下降;当最大化一个效用函数时,使用梯度上升发。
- 在线性回归中使用的是最小二乘法得到最终结果,而对于许多机器学习算法,其最小化损失函数的方法是不能使用类似最小二乘法直接求解的。此时可以考虑借鉴数值计算方法中的凸优化问题的解法。
- 目标函数是参数的函数,输入数据是常量。所以目的是找到目标函数取最小值时的参数。
- 搜索可能陷入局部最优解,解决方法有比如动量梯度下降,跳出局部最优值。还可以多次运行GD,每次的起始点随机化。
- 线性回归问题的目标有唯一的最优解,(凸优化问题)
- 当目标函数是凹函数时,才求最小值。目标函数对参数求导数,得到梯度。梯度表示这一点的切线斜率的值。根据参数迭代公式:当在某一点的梯度小于0时,迭代后参数值增大,即对应的目标函数值减小;当在某一点的梯度大于0时,迭代后参数值变小,即目标函数值减小。可见,不管点的位置在哪,迭代参数后,目标函数值都减小。(详见数学笔记)
模拟梯度下降
先创建一个数据集,使其图像为凹函数:
1 | x = np.linspace(-1, 6, 200) |
x为参数,y为目标函数。y对x求导数:
1 | def gradient(theta): |
对x求对应y:
1 | def loss(theta): |
根据迭代公式,编码:
1 | learning_rate = 0.1 |
其中,epsilon是一个很小的值,当abs(loss(theta)- loss(last_theta)) < epsilon时,表示迭代参数使得目标函数值达到最小值。为什么不是当梯度为零停止迭代呢,因为浮点数0,在计算机中不是零,这样,就本实验而言循环不会停止。
theta_history记录了每次迭代的参数值。
当learning_rate = 0.1,theta = 0时绘出函数图像,及参数迭代路径:
1 | plt.plot(x, y) |
如图:
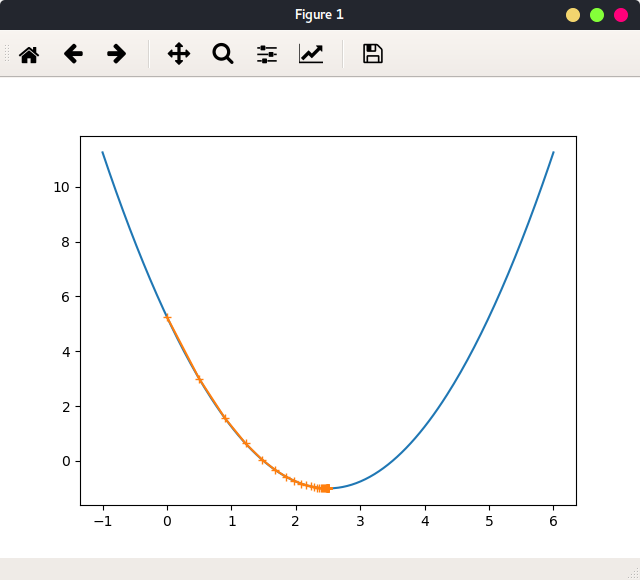
一共迭代了46次,最终停在点(2.499891109642585, -0.99999998814289),与最小值点(2.5, -1)非常接近。这表明了算法的正确性。
当当learning_rate = 0.1,theta = 5.5时绘出函数图像,及参数迭代路径:
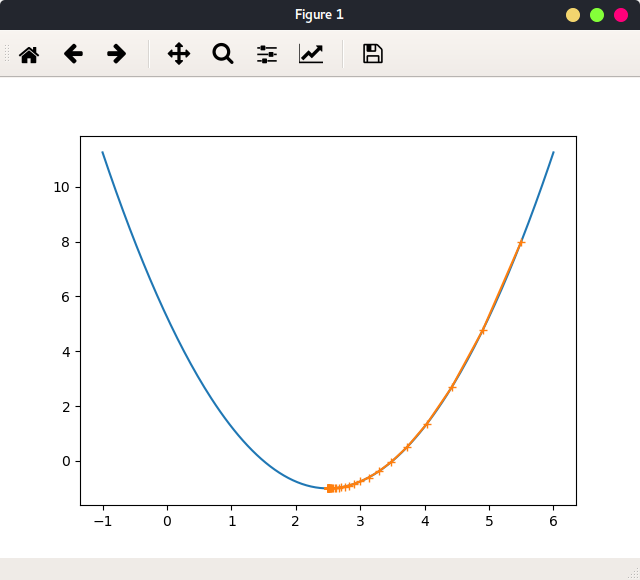
可以看出,不论参数初始值在哪,最终会停在最小值处。
当学习率较小时:learning_rate = 0.01,theta = 5.5绘出函数图像,及参数迭代路径:
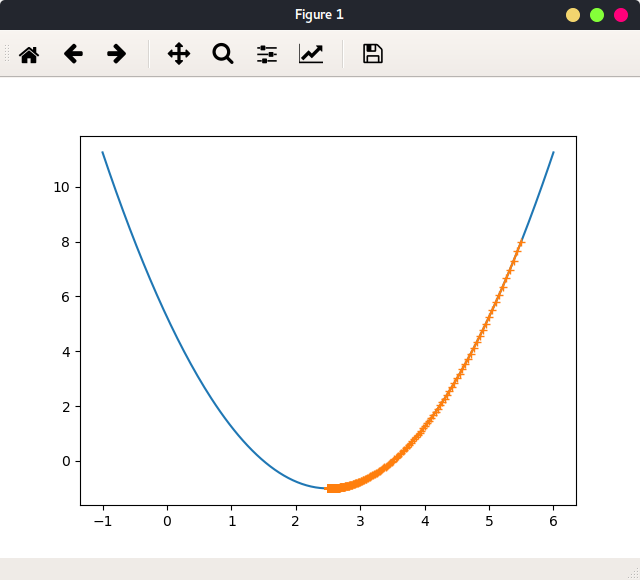
依旧停在最小值处,但是迭代次数增加到433次。
当学习率较大时:learning_rate = 0.9,theta = 5.5绘出函数图像,及参数迭代路径:
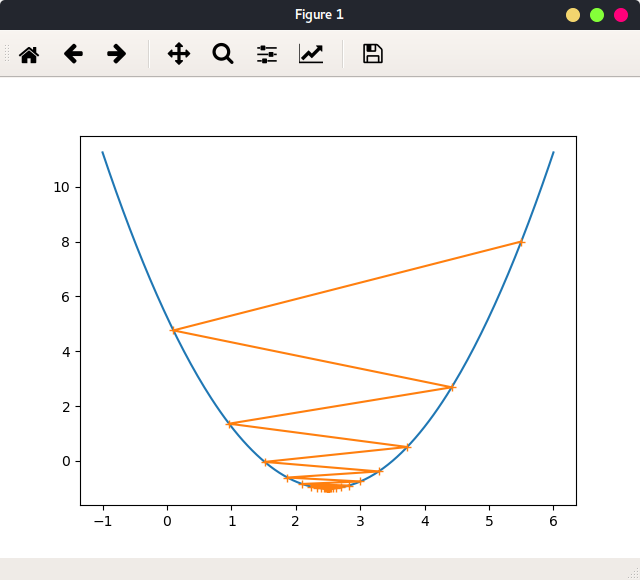
可以看出,学习率较大时,迭代路径在最优值左右震动。
为了避免迭代无止境的循环下去,设置参数n_itr,表示最大迭代次数。
当设置学习率过大时,learning_rate = 1.1``theta = 0,n_itr=5,出现梯度上升情况,如图:
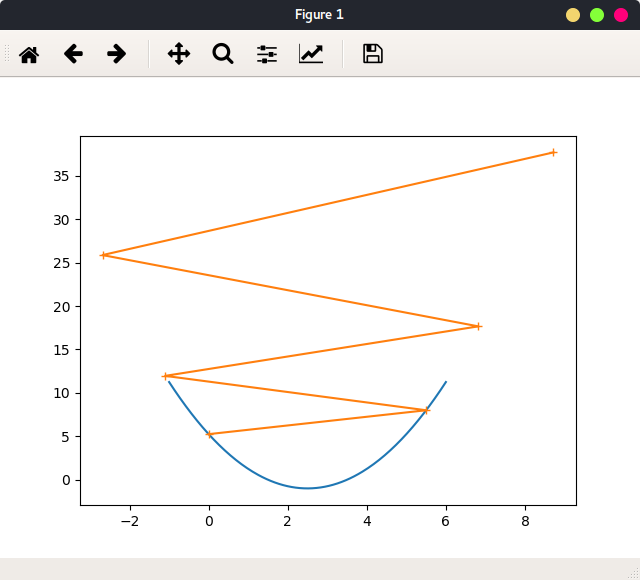
限定只迭代5次。
所以要设置最合适的学习率。
程序
以上实现过程:
1 | def gradient_descent(init_theta, learning_rate, n_itr, epsilon=1e-8): |
调用:
1 | learning_rate = 0.1 |
多元线性回归的GD
python数据行为
创建一个一维向量:
1 | np.random.seed(123) |
x1的内容如下:
1 | [ 1.39293837 0.57227867 0.45370291 ... 1.10262954 1.43893794 ] |
x1是一个长度为100的一维向量。向量每个元素为一个标量。用 同样的方式在创建一个等长度的一维向量x2:
1 | x2 = 3 * np.random.random(size=100) |
假如变量y由x1和x2共同决定:
1 | y = x1 * 3 + x2 * 4 + (5 + np.random.normal(size=100)) |
此时x1和x2作为输入样本的两个特称,现在把两者合并在一起:
第一步变形为1列:
1 | x1.reshape(-1, 1) |
返回一个二维向量,每一个元素为一个长度为1的一维向量,每一个元素表示一个样本:
1 | [[ 1.39293837] |
第二步,将两个特征合并在一起:
1 | X = np.hstack([x1.reshape(-1, 1), x2.reshape(-1, 1)]) |
返回X为一个二维向量,这个向量的每个元素为一个样本,每个样本由两个值表达:
1 | [[ 1.39293837 1.53938446] |
因为y的组成还有一个常量,可以用x0表示,x0恒为1,并且把x0也X中:
1 | X_b = np.hstack([np.ones((len(X), 1)), X]) |
返回X_b 中每个元素由3个值决定:
1 | [[ 1. 1.39293837 1.53938446] |
现在可以看看X_b 的属性:
1 | print(type(X_b)) |
返回:
1 | <class 'numpy.ndarray'> # 是一个 numpy.ndarray 对象 |
100行表示,一共有100个样本,3列表示每个样本有3个特征。
因为此时X_b是一个矩阵,所以还可以对X_b进行切片操作,就是取它是一部分:
取索引为0的元素,即第一行,所有列:
1 | print(X_b[0, :]) |
取所有行,索引是0和1的列:
1 | print(X_b[:, 0:2]) |
其他函数的用法:np.ones((4, 2)):创建矩阵4行2列。
dot()
.dot() 是numpy.ndarray对象的方法,实例:X_b是100X3的矩阵,theta为长为3的向量,y为长度为100 的向量,则:
X_b.dot(theta) 结果为长度为100 的向量。y - X_b.dot(theta)结果为长度为100的向量。(y - X_b.dot(theta))**2 结果为长100 的向量。平方差。
np.sum((y - X_b.dot(theta))**2) 结果为100个数就和。 平方差之和。np.sum((y - X_b.dot(theta))**2) / len(X_b) 就是MSE。
对象.dot(参数)中对象是一个矩阵,它的每一行代表一个样本,所有行表示所有样本。参数是一个向量,这个向量中每一个值分别与对象的每一行的每个值相乘后相加,最后得到一个与参数大小一样的向量。
BGD算法过程
目标:最小化loss:
1 | def loss(theta, X_b, y): |
迭代过程中需要求梯度:
1 | def gradient(theta, X_b, y): |
其中res[i]的值所用公式见数学笔记。
GD的过程如下,输入样本X_b已知, y表示真是拟合值,只需要初始化参数theta就可执行GD。init_theta = np.zeros(X_b.shape[1]) 初始值为0。
1 | def gradient_descent(X_b, y, init_theta, learning_rate=0.01, n_itr=1000, epsilon=1e-8): |
调用GD:
1 | theta = gradient_descent(X_b, y, init_theta, learning_rate=0.01, 2000) |
结果分别对应(5 + np.random.normal(size=100),3,4。
其中,对于求梯度,观察式子,发现可以使用向量化实现:
1 | def gradient_vectorize(theta, X_b, y): |
归一化
当样本的每种特征数值量级差别很大时:
1 | [ 6.32000000e-03 1.80000000e+01 2.31000000e+00 0.00000000e+00 |
使用一般的步长,得到的结果在python中为nan。因为特征数值相差太大时,一般的步长也变得很大很大(步长对数据特征值之差敏感)。此时减小步长,增加迭代次数也就可以达到结果,但效率很低。
所以使用梯度算法前,要对数据进行归一化。
SGD
随机梯度下降法,每次处理一个样本,马上计算一次梯度(见数学笔记)。与BGD相比,SGD的loss函数改变了:
BGD的loss是将所有样本带入目标函数后的结果(看公式)。而SGD的loss是把当前这一个样本带入目标函数的结果。
所以,BGD的参数迭代路径的方向是由所有样本决定,是实际方向。而SGD的参数路径是曲折的,因为每一步只是由一个样本得到,这个方向不能代表所有样本的实际方向。
SGD一般设置学习率为变化值。learning_rate = a / (itr+b)。
SGD实现:
1 | def gradient_vectorize(theta, X_b_i, y_i): |
敲黑板
- 本篇笔记的GD算法是一次性把所有样本带入,也就是遍历一遍所有样本才更新一次参数。称为BGD
- 向量化速度快
- 与步长有关的迭代算法,首先要对数据进行归一化。
- 常用python函数
- BGD和SGD的loss函数是不同的,BGD在迭代过程中目标函数不变,而SGD的loss随每个样本而改变。