Unified Memory
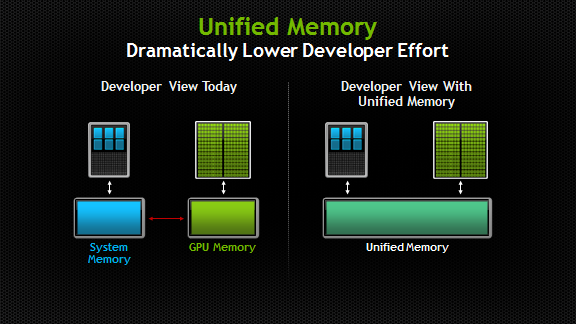
Unified Memory 是个逻辑概念,就像字面上所说,把Host内存和Device内存逻辑上放到一起,如此一来,对于程序员来说,就没有Host和Device之分了,表面上就更容易编写程序了。如下图所示。
“Unified Memory creates a pool of managed memory that is shared between the CPU and GPU, bridging the CPU-GPU divide. Managed memory is accessible to both the CPU and GPU using a single pointer. The key is that the system automatically migrates data allocated in Unified Memory between host and device so that it looks like CPU memory to code running on the CPU, and like GPU memory to code running on the GPU.”
如下是使用Unified memory一般情况:
1 | // Allocate Unified Memory -- accessible from CPU or GPU |
但是注意了,使用这种方式时,要加上cudaDeviceSynchronize()。保证
“Just one more thing: I need the CPU to wait until the kernel is done before it accesses the results (because CUDA kernel launches don’t block the calling CPU thread). To do this I just call cudaDeviceSynchronize() before doing the final error checking on the CPU.”
这种方法使得在逻辑上,xy不区分是存在于host 还是存在于device
原文作者Mark Harris
原文链接
CUDA