存储优化
重叠内存传输和计算,组团传输减少小块数据的频繁传输。
现代GPU对访存做了优化,使得不是严格的Coalescing Access也是可以接受的。但是
- 避免凌乱无规律的访存
- 避免一个线程访问连续的一段空间。
将global memory中的数据放入shared memory中,使得数据的位置相邻后写入global memory,此时相邻的threads就可以访问相邻的地址,满足Coalescing Access。shared memory的设计目的之一就是通过对它的编程,来规则化访存模式。
回忆:shared memory的架构是连续32 bits(即4 Bytes)的地址被分配到连续的bank中。见下图:
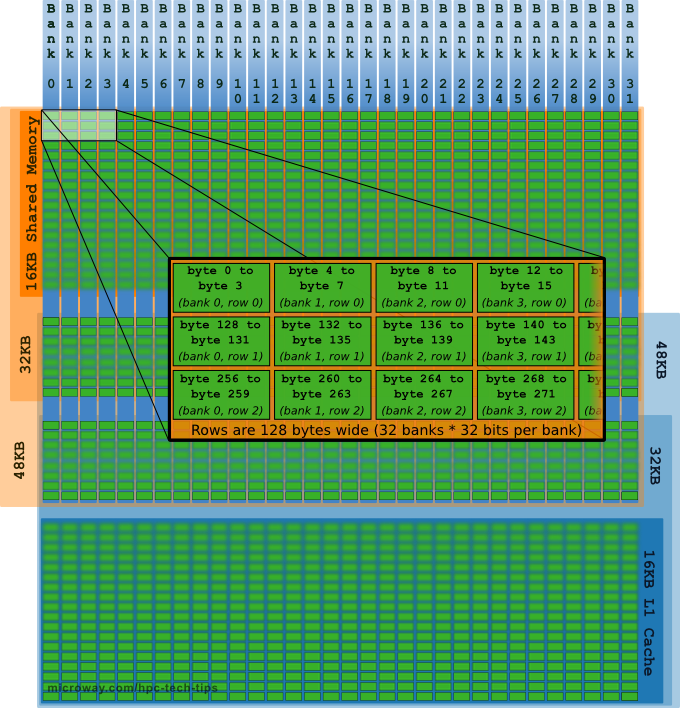
原图来自这里。里面有不少其他资源可参考。
对于bank冲突,注意理解地址的编号和bank的编号的不同。
注意
Coalescing access是就global memory而言的。
存储优化,优化实列:矩阵转置
未优化的矩阵转置
对global memory的读和写总有一个,对global存储的地址访问不是连续的,这就不能最大化coalescing access。看下图:
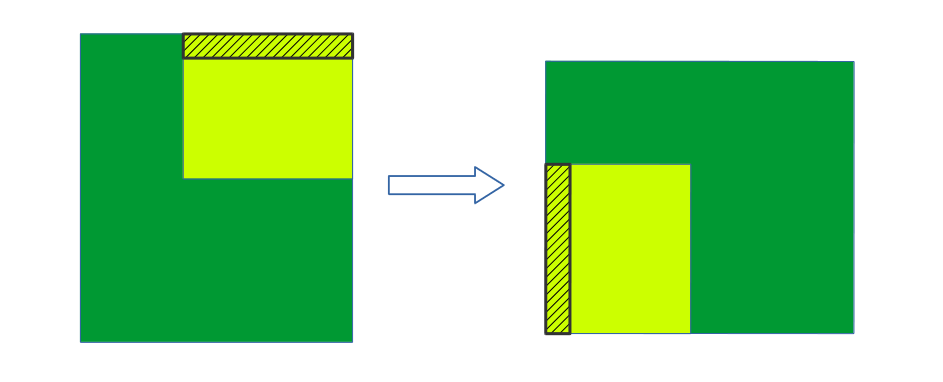
每个block负责矩阵的一个子块(tile),所有子块并行执行。
TILE_DIM=blockDIm.x。1
2
3
4
5
6
7
8
9
10
11
12__global__ void transpose(float* a, float* b){
// 每个线程的id
int idx = threadIdx.x + TILE_DIM * blockIdx.x;
int idy = threadIdx.y + TILE_DIM * blockIdx.y;
// 每个数据转置前后,在矩阵中的索引
int index_a = idx + WIDTH * idy;
int index_b = idy + HEIGHT * idx;
// 转置操作
b[index_b] = a[index_a];
}所以:
使用shared memory优化的矩阵转置
在写入global memory之前,先从global中将所读取的元素存入shared memory中,当shared memory中有了所有元素,将此时的shared memory转置一下,最后将结果再写(合并地)入global memory。
如此一来对global的读和写,地址都是被连续访问的。看下图:
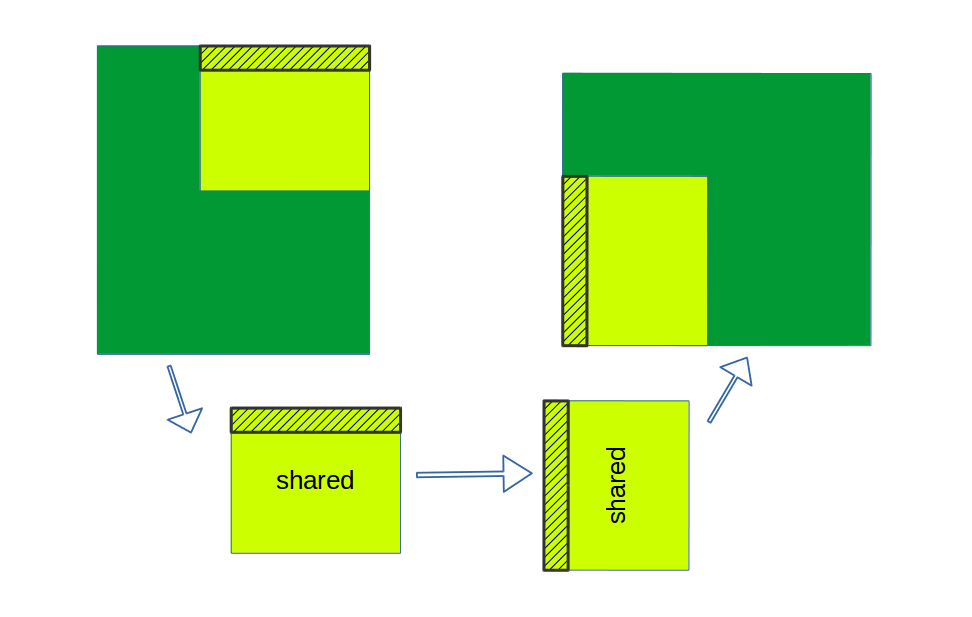
实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25__global_ void transpose(float* a, float* b){
__shared__ float tile[TILE_DIM][TILE_DIM];
// 每个线程的id
int idx = threadIdx.x + TILE_DIM * blockIdx.x;
int idy = threadIdx.y + TILE_DIM * blockIdx.y;
// idx 与 idy 线性组合 得到原矩阵的Index
int index_in = idx + idy * WIDTH;
// 每个数据转置前后,在矩阵中的索引
idx = threadIdx.x + TILE_DIM * blockIdx.y;
idy = threadIdx.y + TILE_DIM * blockIdx.x;
// // idx 与 idy 线性组合 得到转置后矩阵的Index
int index_out = idx + idy * HEIGHT;
// 从a中写入到bank中,会产生冲突。(马上解决)
tile[threadIdx.y][threadIdx.x] = a[index_in];
// 等待这个block对应的tile中的 元素都有了之后,再执行下后续操作。
__syncthreads();
// 转置操作
b[index_out] = tile[threadIdx.x][threadIdx.y];
}在Shared memory中存在bank冲突,如何解决。
解决上述过程中的bank冲突
对于上述实现过程中
tile[threadIdx.y][threadIdx.x] = a[index_in];,如果tile的大小是16x16,那么这一句会产生16路的bank冲突。 !!!如何理解bank的编号!!!如何解决bank冲突,看下图:
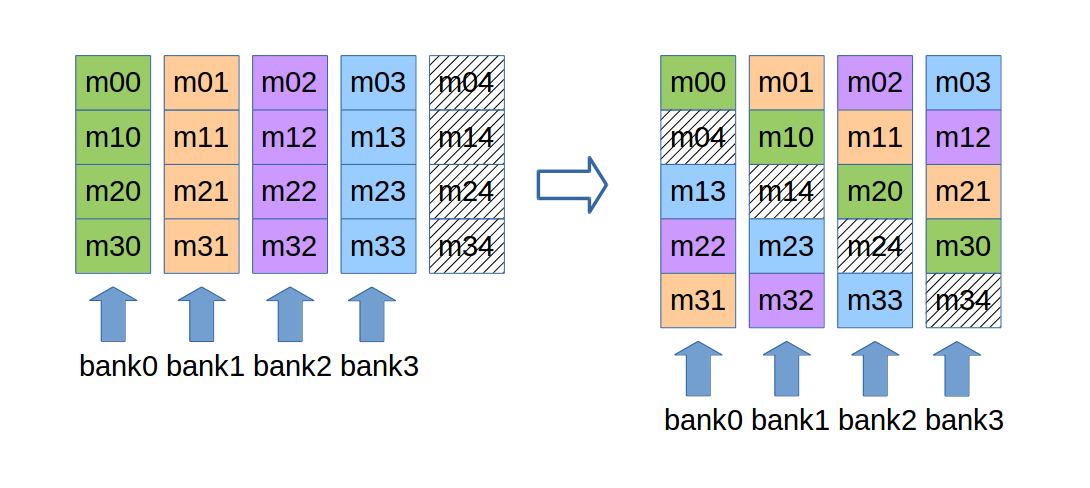
实现中只需更tile的定义为
__shared__ float tile[TILE_DIM][TILE_DIM+1];,列中的数据存于相同的bank。如此一来,不论是对tile行或列的访存,都不会产生bank冲突。相同的颜色在不同的行和列。