好好体会-Dot product
(CUDA by example 55页)
这个例子值得好好感悟
点积:两个长度相同的向量A和B,对应元素相乘后相加。
CUDA实现思路:每个线程分别读取A和B中对应位置的元素,紧接着执行相乘操作,最后将相乘结果存入shared memory的对应位置。
注意,当向量元素个数远远超过一个block中的threads数量时的处理。
1 | const int N = 33*1025; |
其中这一部分:
1 | float tmp = 0.0f; |
当所有threads的数目小于a或b中的元素个数时(不论有多少个blocks),上述保证正确,与stride更新效果相同。当threads个数等于元素个数时,也正确。所以这样写,分析见下图:
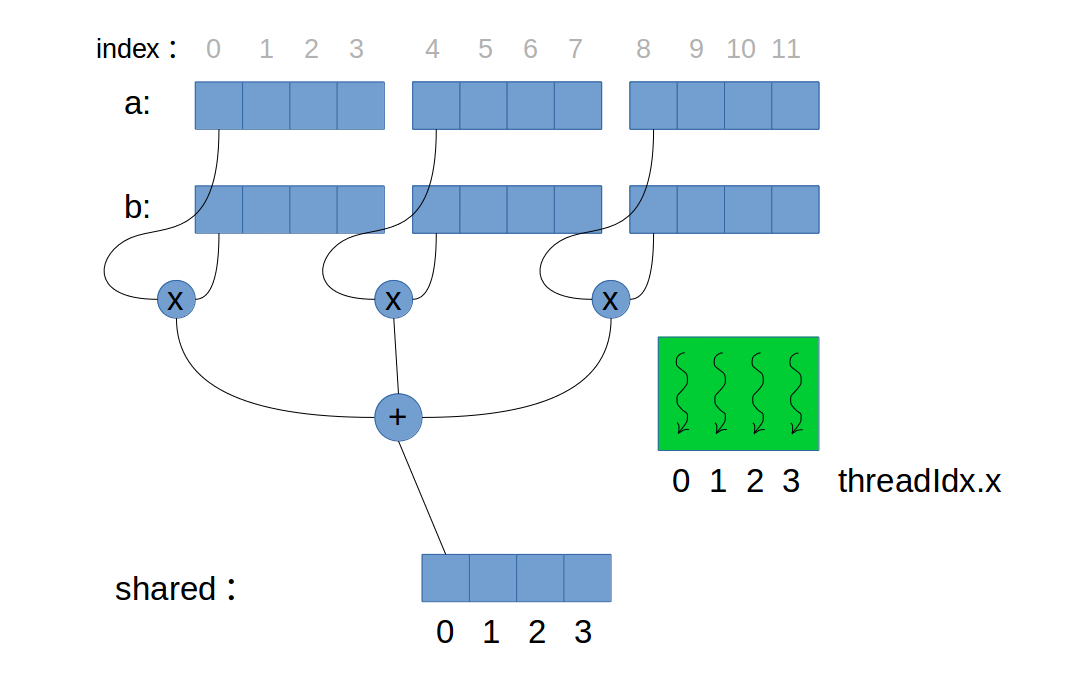
上图中只使用了一个block,所以在第二步归约计算时,就可以在第0个位置上得到最终结果。当使用多个blocks时,第二步得到每个block的第0个元素,而这些若干个第0个元素保存于c(Global)中,最终还要将c中元素求和。
而下面这种实现:
1 | if (tid<N){ |
只适用于thread个数等于元素个数时(如下图)。但通常元素个数会远大于threads数。所以不适用此法。
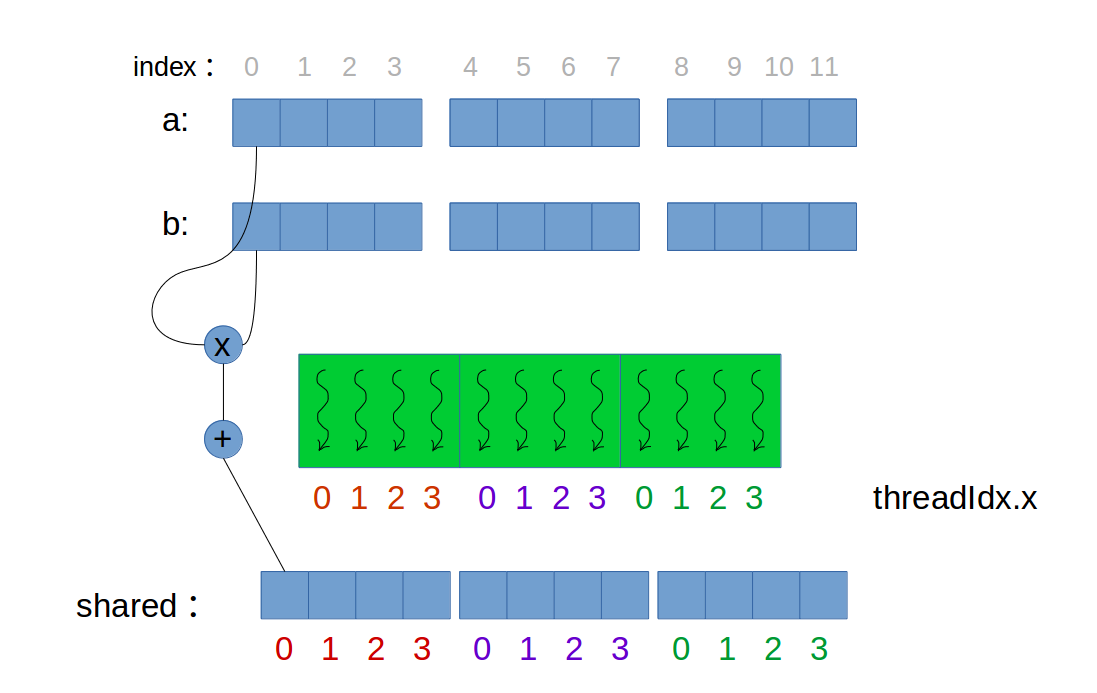
技能:多个blocks中的各个shared memory 缓存同时被操作。
为什么要将最后的结果传回host计算?
因为,事实证明,想GPU这种大规模并行机器在执行最后的规约步骤时,通常会浪费计算资源,因为此时的数据集非常小。比如,当使用480 个threads将32 个数相加时,将难以充分使用每一个threads。
总结一下,使用shared memory优化dot-production为什么有效,因为减少了写入global memory的次数,并且复制回host的数据量减少。性能增加。
敲黑板注意threadIdx.x 与threads ID的区别,前者相对ID后者绝对ID。访存Shared memory时,一定使用threadIdx.x。
__syncthreads() 放错位置会导致死锁
规约程序中:
1 | int i=blockDim.x/2; |
如果将__syncthreads()放入if语句,会产生死锁:
1 | int i=blockDim.x/2; |
解释一下,当出现线程发散时,发散的分支会使得某些threads处于空闲状态,而其他threads将执行分支中的代码。而对于__syncthreads()而言,CUDA架构确保,一个block中的所有threads都执行到__syncthreads(),才能执行__syncthreads()之后的语句。这样一来,上述代码块,只要有一个threads没有执行if语句,也就不能够执行__syncthreads(),其他执行了if语句的threads会等待哪一个thread,一直等下去,造成死锁。
所以,对于__syncthreads()要谨慎使用。