Layer和Net
caffe中的每个层对象,都是一个模型的基本计算单元。一个层对象包括 “…filters, pool, take inner products, apply nonlinearities like rectified-linear and sigmoid and other elementwise transformations, normalize, load data, and compute losses like softmax and hinge”。见官方文档
几乎所有的层类都会继承自Layer类:class caffe::Layer<Dtype> 这些层类必须实现一个 Forward(), 它接受一个input Blob(bottom)计算输出的Blob(top)。还要实现一个 Backward(),它使用给定其输出Blob的误差梯度,计算相对于其输入Blob的误差梯度。(实现反向传播)
每个层对象一定包含三个基本方法:setup(),forward(),backward()。
- setup():一些计算前的操作,用来初始化层。
- forward():前向计算。多个Layer构成一个Net,一个Net中连续的前向传播由
Net::Forward()实现。 - backward():官方文档解释的很好:“given the gradient w.r.t. the top output, compute the gradient w.r.t. to the input and send to the bottom. A layer with parameters computes the gradient w.r.t. to its parameters and stores it internally.”。其中
w.r.t.表示“with respect to”,中文表示“对…(求梯度等操作)”。这就是反向对参数求梯度的过程。当多个层链接到一起,就会形成反向传播的链条(对应了链式法则)。这个链式法则在Net::Backward()中实现
前向计算和后向计算都有CPU和GPU版本的实现。实现自己的层也是不难的,只需要定义好上述三个关键方法。
这里是管方文档中所有的层。
这里是caffe中的前向传播和后向传播的官方描述。
一个Net由多个Layer构成,如下面一个计算图(有向无环图):
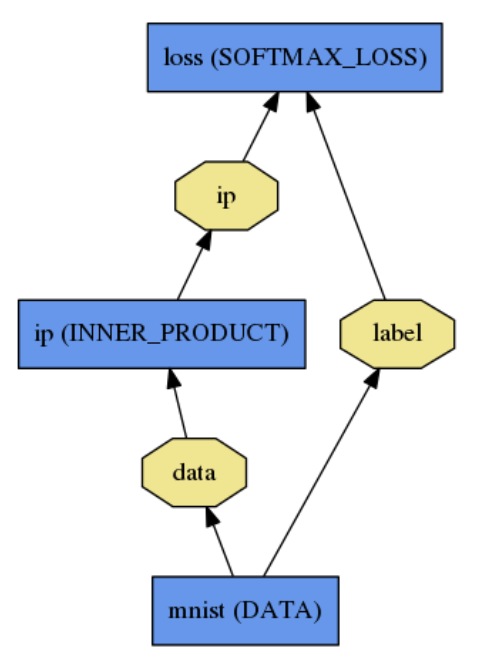
其中蓝色矩形表示layer,里边的小写表示层的name,大写表示层的type;黄色多边形表示在图中游走的数据Blob,数据移动方向从下向上,下为bottom,上为top。这个图对应的.prototxt如下:
1 | name: "LogReg" |
这个Net的初始化通过执行Net::Init(),其作用是生成Blob和Layers,并调用Layer的setup函数。终端的输出信息表示caffe还有记录的工作被执行。
用Caffe::mode()和Caffe::set_mode()指定使用CPU或GPU执行.CPU和GPU的切换是无缝的,与模型的定义是无关的。
模型的定义在机器中是以protocol buffer schema (prototxt)形式存在的。对应训练好的模型是以binary protocol buffer (binaryproto)存在与磁盘的,就是相应路径中的.caffemodel文件。
模型在caffe中的格式。prototxt由caffe.proto解析。细节见这里本地路径:caffe-ROOT/src/caffe/proto/caffe.proto。所使用的技术是Google Protocol Buffer通过科学上网查看。
为什么要使用protocal buffer来格式化模型?
因为,你哪里见过一边砌墙一边烧砖的。使用 protobuff 将整个流程分开,实现每一个组件,之后在将所需的组件拼接起来,最后训练。
Blob
Blob为模型提供数据和数据载体,在模型的正向反向传播中移动。它还提供了CPU和GPU间的同步机制。Blob中的数据可以是一批图像,模型参数,中间计算结果。在Blob中不同类型的数据,其大小是不同的。
图像数据Blob,其中的数据是4维的:
(N, K, H, W)分别表示batch size,channel数量,长和宽。当一个Blob对象中的数据变化时,变化优先级从右向左。所以索引为(n, k, h, w)的数值在物理存储中的索引是((n×K + k)×H + h)×W + w。对于非图像的数据,使用2D Blob,(N, D),此时通常与
InnerProductLayer一同使用。对于参数Blob,其维度要具体问题具体分析了。比如对于conv层,由64个conv kernel,一个kernel的大小是11×11,输入通道数为3,那么此情况的参数Blob大小为(96,3,11,11)。而对于全连接层或上述的
InnerProductLayer,如果输出1000维,输入1024维,那么此情况的参数Blob大小为(1000,1024)。
Blob数据一旦定以好后,caffe的模块化就可以做剩下的工作了。
Blob细节
通常我们关心Blob中的数值(一般的数据,比如一批输入图像)和梯度值。所以一个Blob由两块儿存储:data和diff。
更进一步,Blob中的数值有两种访问的方式,cont和mutable,前者数值不变,后者数值可改变。比如
1 | const Dtype* cpu_data() const; |
同样的,对于cpu_diff和gpu_data, gpu_diff 也有两种访问方式。
Blob为什么要如此设计?
官方文档给出如下解释:
Blob使用
SyncedMem类实现CPU与GPU间的数据拷贝,目的是隐藏延时。如果不想更改数值,那么始终使用const方式调用,而且永远不要将指针存储在自己的对象中。每次处理Blob时,都要调用函数来获取指针,因为
SyncedMem类需要这个函数来确定何时复制数据。在实际中,调用设备内核来执行GPU计算的同时,CPU将数据从磁盘加载到Blob,并将Blob转移到下一层,这是GPU和CPU延时隐藏的基本技巧。因为大部分层都有GPU实现,所以所有的中间数据和梯度都将保留在GPU的内存中。
其他原因如,Blob与其他深度学习框架的数据结构相对应,tensorflow中的tensor,cuda-convnet中的NVMatrix,等,这使得框架之间的转换更容易。
Blob中数据在CPU和GPU之间拷贝行为
假设数据在CPU(Host)上被初始化,存在于一个Blob中。
1 | // 定义一个const访问指针,一个mutable访问指针 |