https://docs.nvidia.com/cuda/archive/12.0.1/cuda-c-programming-guide/#warp-matrix-functions
阅读学习策略:
Doc 中内容太多,短时间内读不完,完全读完性价比太低。所以:
快速浏览,快速了解每一章大概内容。(TODO)- 根据各个框架中的 Op 中 CUDA 实际实现和场景,选择 doc 中的重点内容理解。(NEW DOIT)
CUDA 最新 doc
1. Introduction
核心包含三个关键抽象:
- 线程组层次结构
- 共享内存
- 屏障&同步
2. Programming Model
内核函数在被调用时,将由 N 个不同的 CUDA 线程并行执行 N 次。
程索引与其线程 ID 之间的关系非常直接:对于一维块,它们是相同的;对于大小为(Dx,Dy)的二维块,索引为(x,y)的线程的线程 ID 是(x + y*Dx);对于大小为(Dx,Dy,Dz)的三维块,索引为(x,y,z)的线程的线程 ID 是(x + y*Dx + z Dx*Dy)。
每个块中线程的数量是有限的,因为一个块中的所有线程都预期驻留在同一个流式多处理器核心上,并且必须共享该核心有限的内存资源。在当前的 GPU 上,一个线程块可能包含多达 1024 个线程。
线程块必须能够独立执行。这意味着,如果一个线程块中的所有线程都执行相同的代码,那么它们将按照相同的顺序执行该代码。
线程块内的线程可以通过共享内存和同步执行来协作,以协调内存访问。__syncthreads(), 此外,Cooperative Groups API 还提供了一套丰富的线程同步原语。
在一个 Block 内,为了高效协作,Shared Memory 位于每个处理器核心附近(类似于 L1 缓存),并且 __syncthreads() 相对是轻量级的。
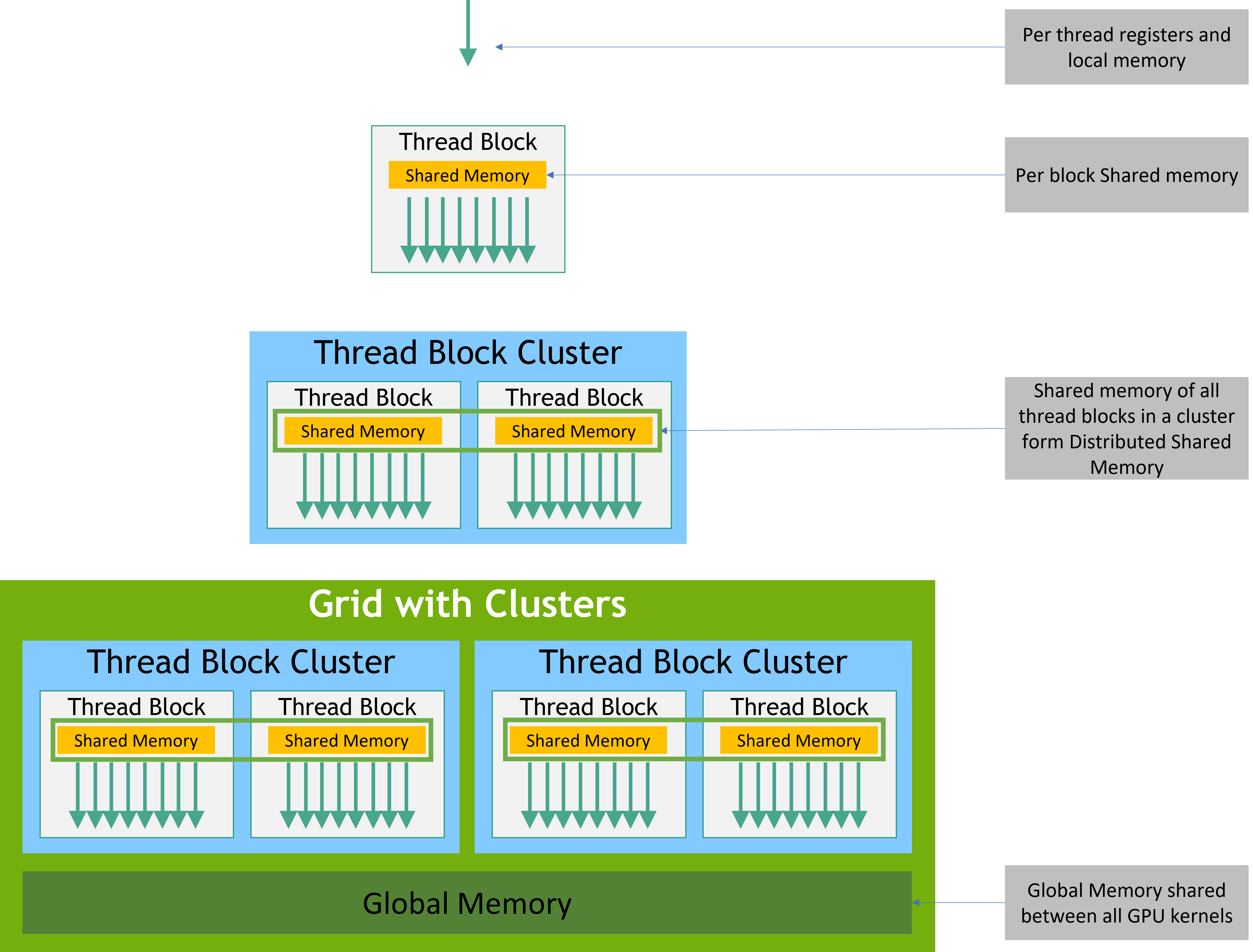
Thread Block Clusters(TBC):
计算能力 9.0 中,CUDA 编程模型引入了一个可选的层次结构,称为线程块集群,它由线程块组成(类似之前的 Grid)。大小由架构决定,可以使用 cudaOccupancyMaxPotentialClusterSize API 进行查询。gridDim 变量仍然表示线程块的数量,以保持兼容性。
在内核中,可以通过编译时内核属性使用 __cluster_dims__(X,Y,Z) 或者使用 CUDA 内核启动 API cudaLaunchKernelEx 来启用线程块集群。
- 前者在 launch kernel 时,需要给出
<<< >>>给出线程配置。无法更改 cluster 的配置。 - 后者在运行时决定 cluster 配置,然后通过调用
cudaLaunchKernelEx,启动kernel。
9.0 计算能力的 GPU 中,集群中的所有线程块都保证在单个 GPU 处理集群(GPC?)上协同调度,并允许集群中的线程块使用 Cluster Group API cluster.sync() 进行硬件支持的同步。集群组还提供了成员函数,分别使用 num_threads() 和 num_blocks() API 查询集群组的大小。
线程块属于同一集群时,可以访问分布式共享内存(Distributed Shared Memory, DSM),仅适用于 Hopper 架构。
存储层次结构:
有4个层次,见图:
https://docs.nvidia.com/cuda/cuda-c-programming-guide/_images/memory-hierarchy.png
{kind=link}
TBC中有多个线程块,每个线程块有自己的Shared Memory。多个线程块自己的Shared Memory是独立的。这些Shared Memory 一同构成了 分布式共享内存。
Heterogeneous Programming
host 串行 + Device 并行。这里提到 Unified Memory?
Asynchronous SIMT Programming Model
NVIDIA Ampere GPU 架构的设备开始,CUDA 编程模型通过异步编程模型 为内存操作提供加速。
异步编程模型定义了 Asynchronous Barrier?,用于 CUDA 线程之间的同步。The model also explains and defines how cuda::memcpy_async can be used to move data asynchronously from global memory while computing in the GPU.
Compute Capability
SM 版本表达了计算能力
设备具有相同的重大版本号,则属于相同的核心架构:
- 基于 Hopper GPU 架构的设备的重大版本号为 9,
- 基于 Ampere GPU 架构的设备的重大版本号为 8,
Turing 是基于 Volta 的升级版,其 SM 版本是7.5- 基于 Volta 架构的设备的重大版本号为 7,
- 基于 Pascal 架构的设备的重大版本号为 6,
- 基于 Maxwell 架构的设备的重大版本号为 5,
- 基于 Kepler 架构的设备的重大版本号为 3。
3. 编程接口
它包含了对 C++ 语言的少量扩展 & 一个运行时库。
- 核心 c++ 语言扩展已在编程模型中引入。它们允许程序员将内核定义为 C++ 函数,并在每次调用该函数时使用一些新的语法来指定网格和块维度。所有扩展的完整描述可以在 C++语言扩展中找到。所有含有 C++ 扩展的文件都需要通过 nvcc 编译。
- CUDA 运行时在 CUDA 运行时库中引入。它提供了在主机上执行的 C 和 C++ 函数,用于分配和释放设备内存、在主机内存和设备内存之间传输数据、管理多设备系统等。
使用 nvcc 编译
内核可以使用 CUDA 指令集架构编写,该架构称为 PTX。但,通常使用 CUDA C++ 更有效(编译器会将 CUDA C++ 转换为 PTX 中间表示)。在这两种情况下,内核都必须通过 nvcc 编译成二进制代码,
这一节解释了 nvcc 作为一个编译器驱动程序 的工作。包括
- 离线编译
- 即时编译
- 二进制兼容性:二进制代码是针对特定架构的。使用编译器选项
-code生成 cubin 对象,该选项指定了目标架构:例如,使用-code=sm_80编译将生成适用于计算能力 8.0 的设备的二进制代码。 - PTX 兼容性:某些 PTX 指令仅支持更高计算能力的设备。例如,Warp Shuffle 函数仅支持计算能力 5.0 及以上的设备。
-arch编译器选项指定了将 C++编译为 PTX 代码时假设的计算能力。因此,包含 warp shuffle 的代码必须使用-arch=compute_50(或更高版本)进行编译。
runtime library【包含了很多重点】
运行时由 cudart 库实现,该库与应用程序链接. 就是这个文件了:libcudart.so