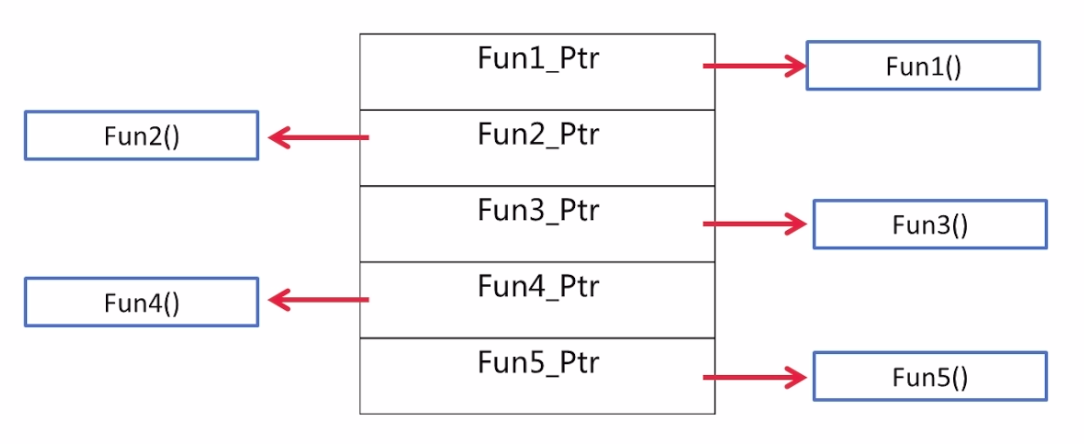
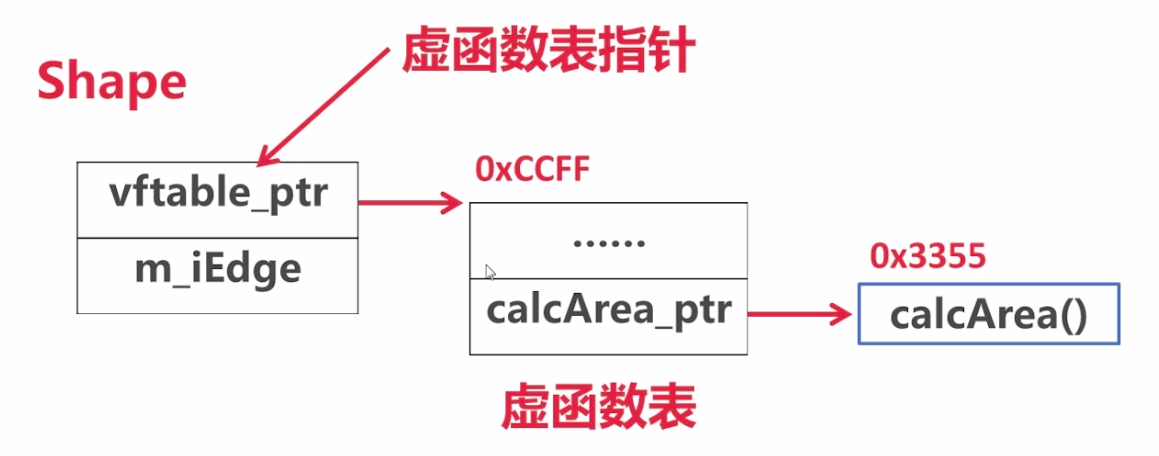
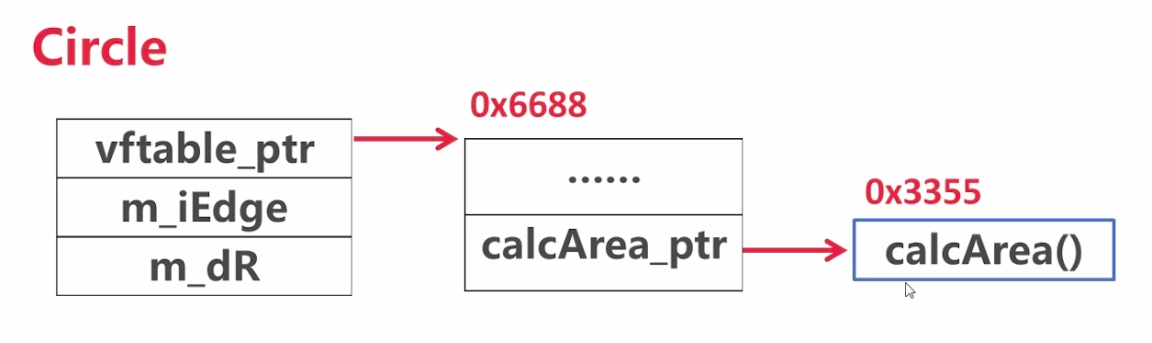
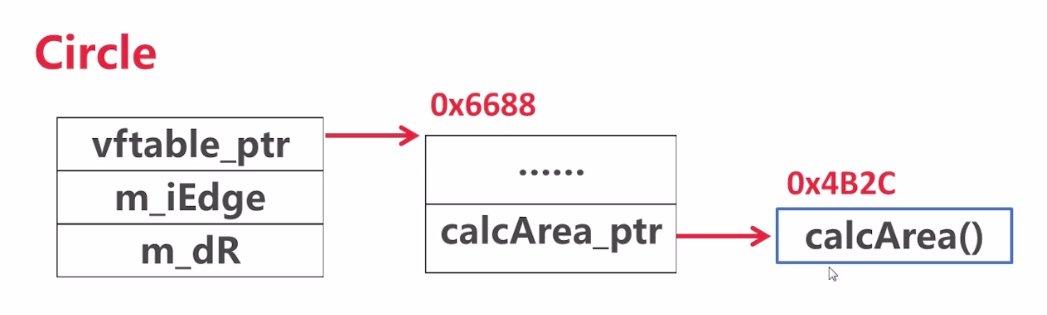
// ID 即姓名 classID{ public: ID(std::string name){ m_strName = name; } voidprintName(){ std::cout<<"candidate name is: "<<m_strName<<std::endl; } private: std::string m_strName; };
Fighter是一个更具体的类,分别继承上述两个接口和一个普通类,并且实现所有的纯虚函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classFighter:public ID, public Diet, public Training{ public: Fighter(std::string name, int trainTime, int numMeal):ID(name){ num_meal = numMeal; time_training = trainTime; }
voidmatch(Fighter* candidate1, Fighter* candidate2){ if (candidate1->timeOfTraining() > candidate2->timeOfTraining()) cout<<"candidate1 is more likely going to win"<<endl; else cout<<"candidate2 is more likely going to win"<<endl; }
intmain(){ // How to use API // 应该实例化“没有被继承的类” Fighter f1("Junhui", 5, 3); Fighter f2("Uunnui", 6, 4);
The above vertical lines are represented by array [1,8,6,2,5,4,8,3,7]. In this case, the max area of water (blue section) the container can contain is 49.
Input: "A man, a plan, a canal: Panama" Output: true Note: For the purpose of this problem, we define empty string as valid palindrome.
实现:
1 2 3 4 5 6 7 8
boolisPalindrome(string s){ for(int l = 0,r=s.length()-1;l<r; l++,r-- ){ while(isalnum(s[l])==false && l<r) l++; //跳过 non alnum while(isalnum(s[r])==false && l<r) r--; //跳过 non alnum if(tolower(s[l]) != tolower(s[r])) returnfalse; } returntrue; }
关键:两指针对撞,跳过,常用字符串函数
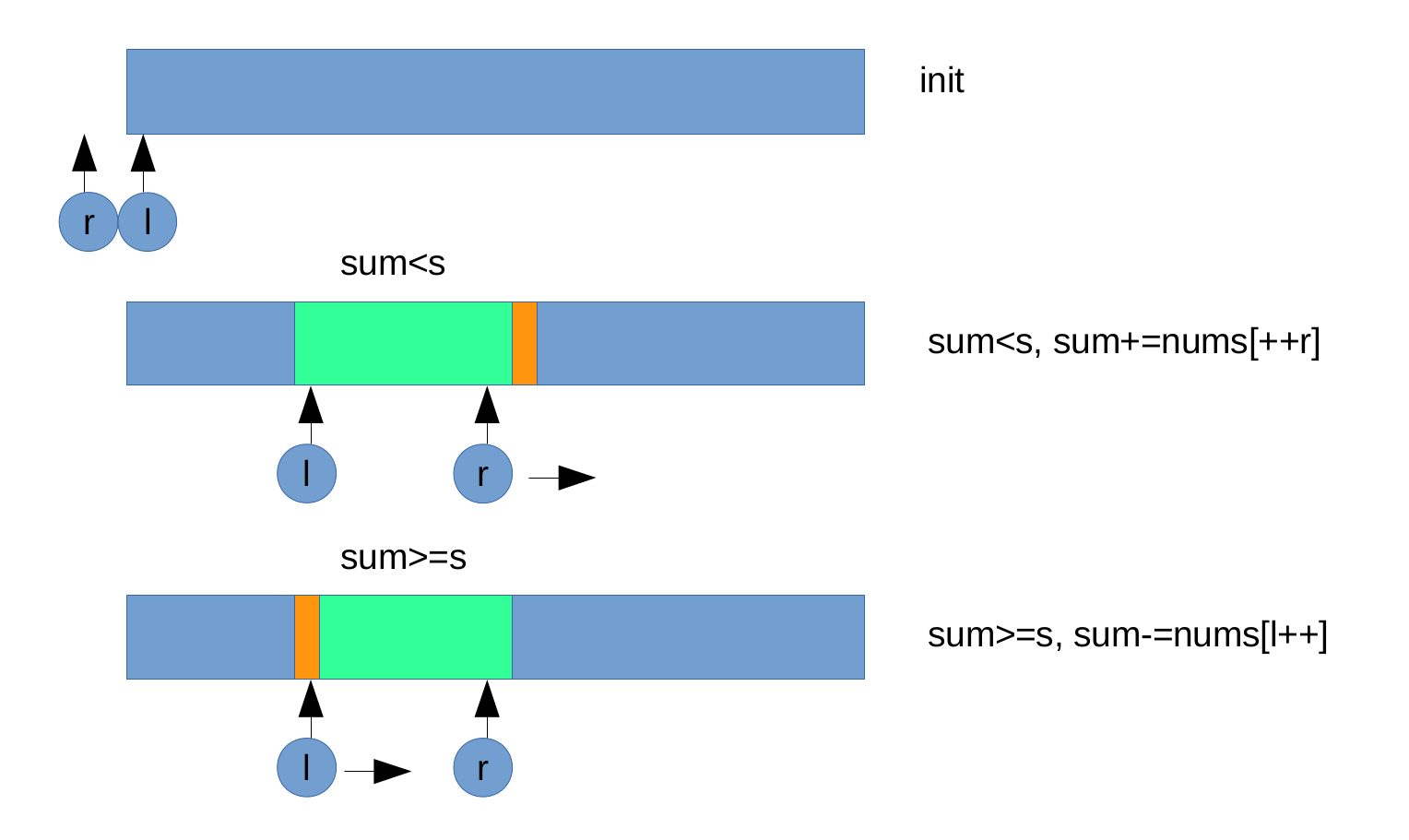
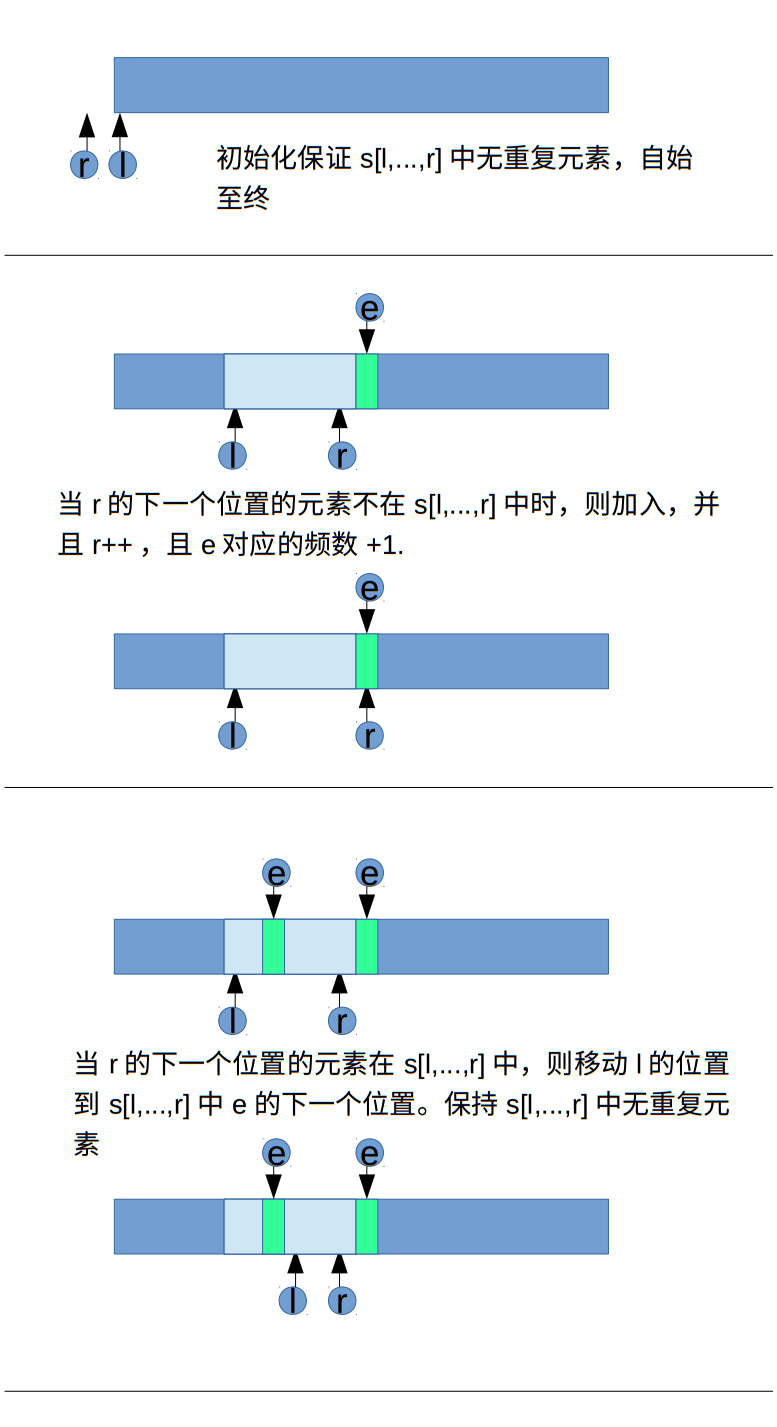
#3 Longest Substring Without Repeating Charactors 最长无重复子串
描述
1 2 3 4
Input: "pwwkew" Output: 3 Explanation: The answer is "wke", with the length of 3. Note that the answer must be a substring, "pwke" is a subsequence and not a substring.
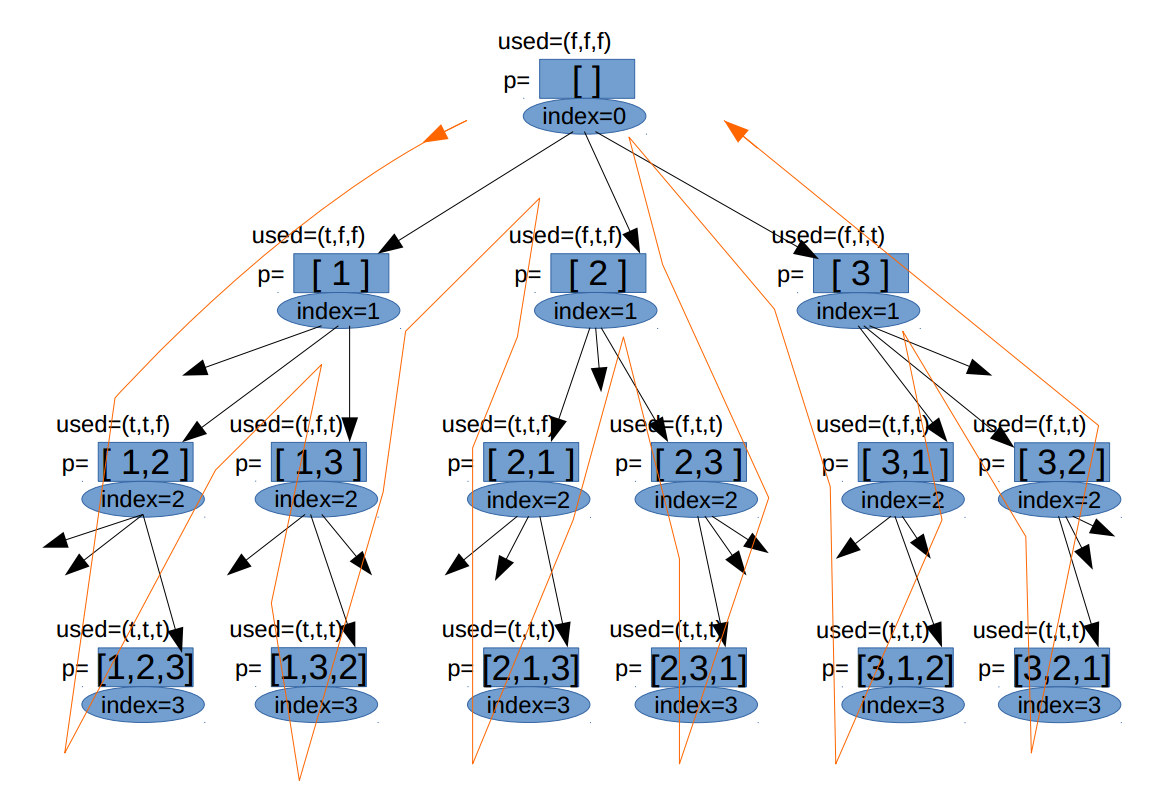
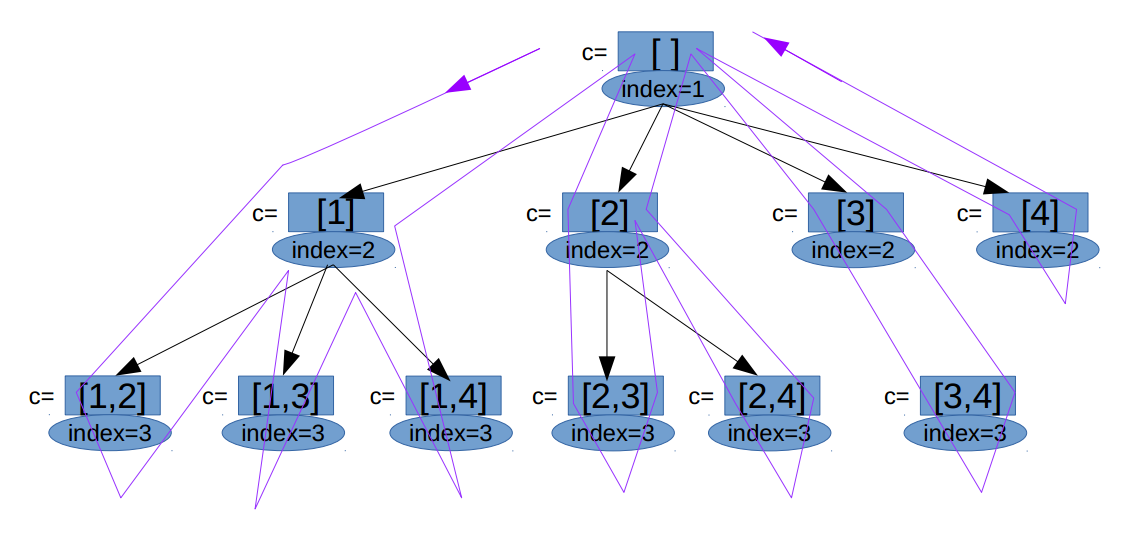
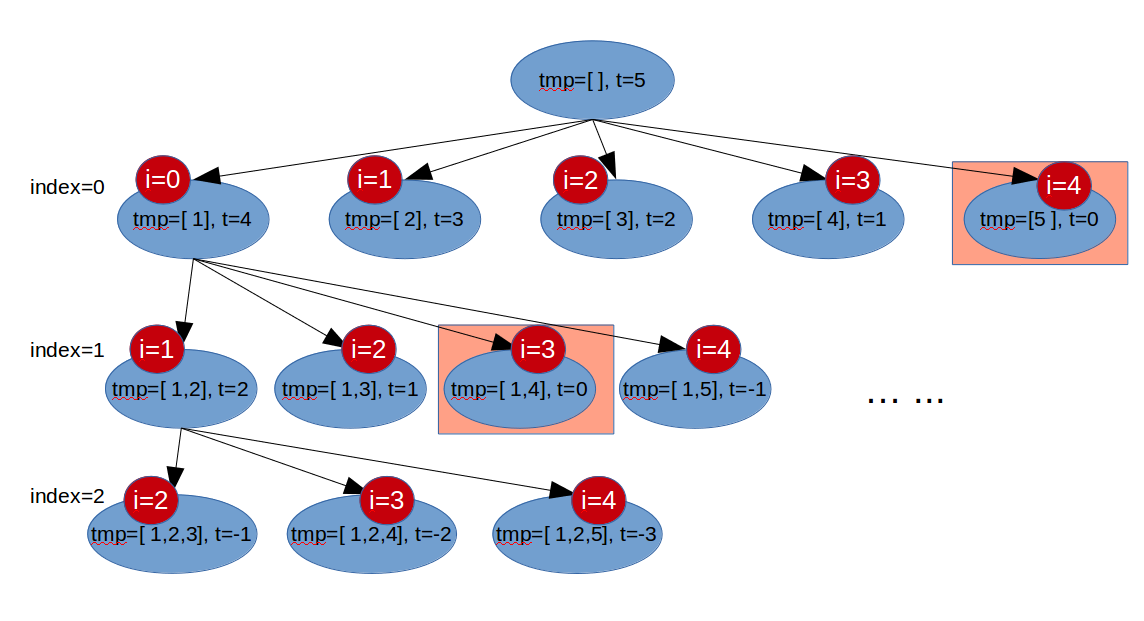
// 定义:从n个数中取k个数,把当前的数值放入c中,从Index开始向后查找: voidgeneratCombination(int n, int k, int index, vector<int>& c){ // 当c的大小为2时,表示找到一个组合 if (c.size()==k){ res.push_back(c); return; }
defpredict(X_sample): assert intercept_ isnotNoneand coef_ innotNone, \ "Must fit before predict" assert X_sample.shape[1] == len(coef_), \ "the feature number of X_sample must be equal to the lenght of coef_" X_b = np.hstack([np.ones((len(X_sample), 1)), X_sample]) return X_b.dot(_theta)