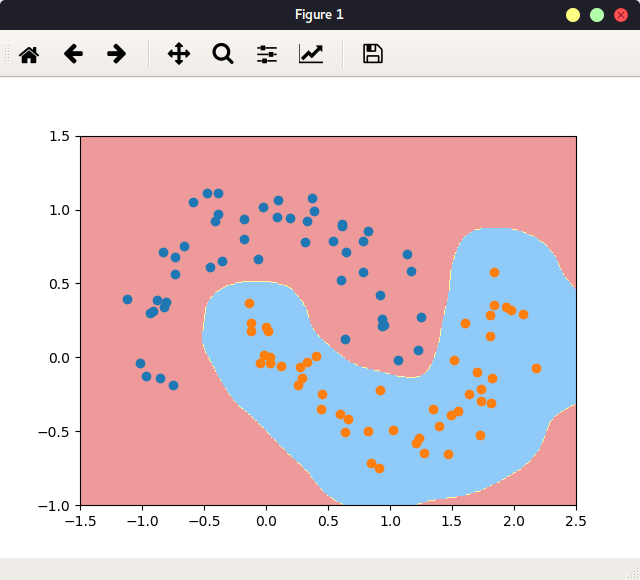
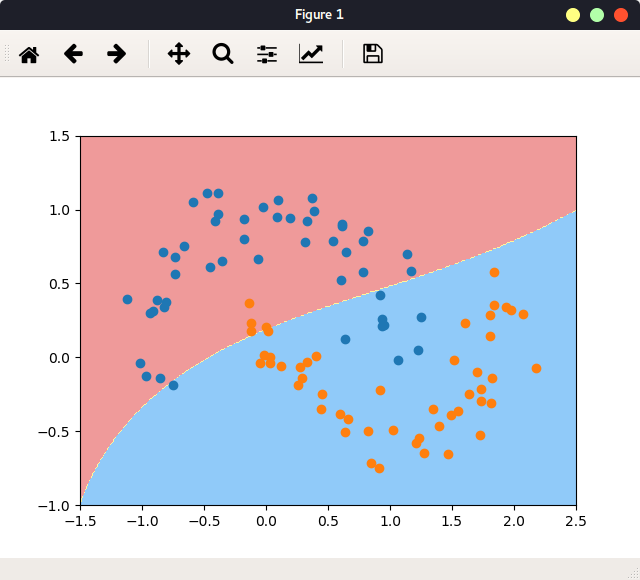
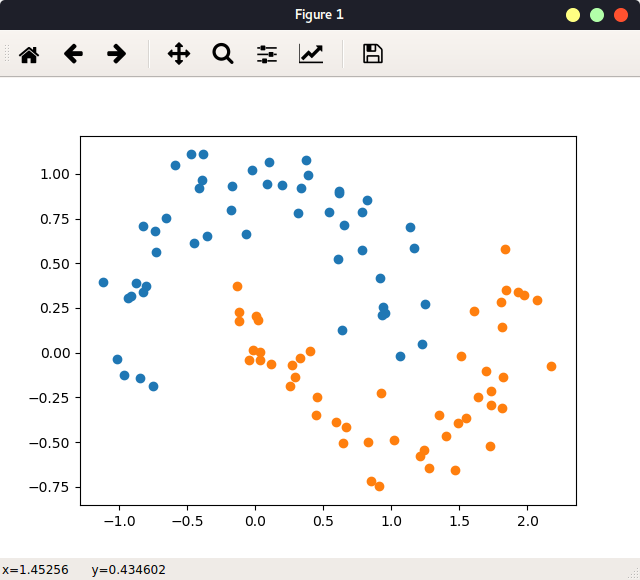
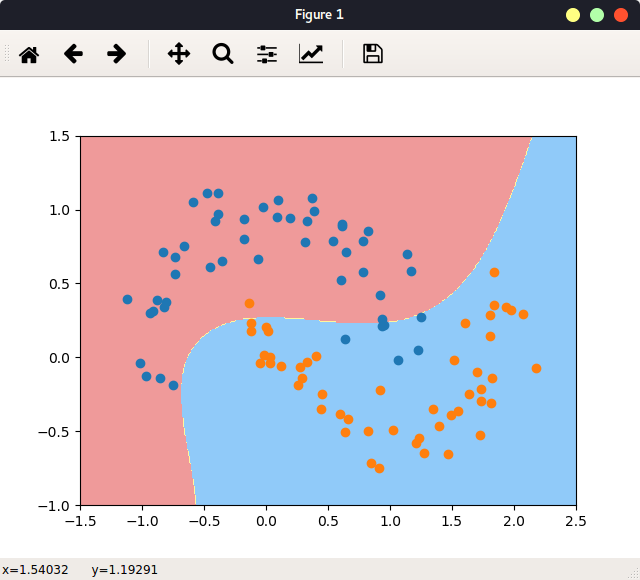
一个实例 检查环境:
nvcc -V:CUDA编译器是否安装nvidia-smi:显卡驱动是否安装
cuda代码文件以.cu结尾,当写好一个文件后,使用NVIDIA 的编译器编译 nvcc FILE-NAME.cu,后./FILE-NAME执行。
从一个实例讲起:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <stdio.h> #define N 1<<10 #define ARRAY_BYTES N*sizeof(float) __global__ void add (float * x, float * y, float * z) { int tid = threadIdx.x + blockIdx.x * blockDim.x; if (tid < N){ z[tid] = x[tid] + y[tid]; } } int main (int argc, char ** argv) float h_a[N], h_b[N], h_c[N]; float *dev_a, *dev_b, *dev_c; cudaMalloc((void **)&dev_a, ARRAY_BYTES); cudaMalloc((void **)&dev_b, ARRAY_BYTES); cudaMalloc((void **)&dev_c, ARRAY_BYTES); for (int i=0 ;i<N;i++){ h_a[i] = i * 1.0f ; h_b[i] = i * 2.0f ; } cudaMemcpy(dev_a, h_a, ARRAY_BYTES, cudaMemcpyHostToDevice); cudaMemcpy(dev_b, h_b, ARRAY_BYTES, cudaMemcpyHostToDevice); add<<<1 , 1024 >>>(dev_a, dev_b, dev_c); cudaMemcpy(h_c, dev_c ,ARRAY_BYTES, cudaMemcpyDeviceToHost); for (int i=0 ;i<N;i++) printf ("%f + %f = %f \n" , h_a[i], h_b[i], h_c[i]); cudaFree(dev_a); cudaFree(dev_b); cudaFree(dev_c); return 0 ; }
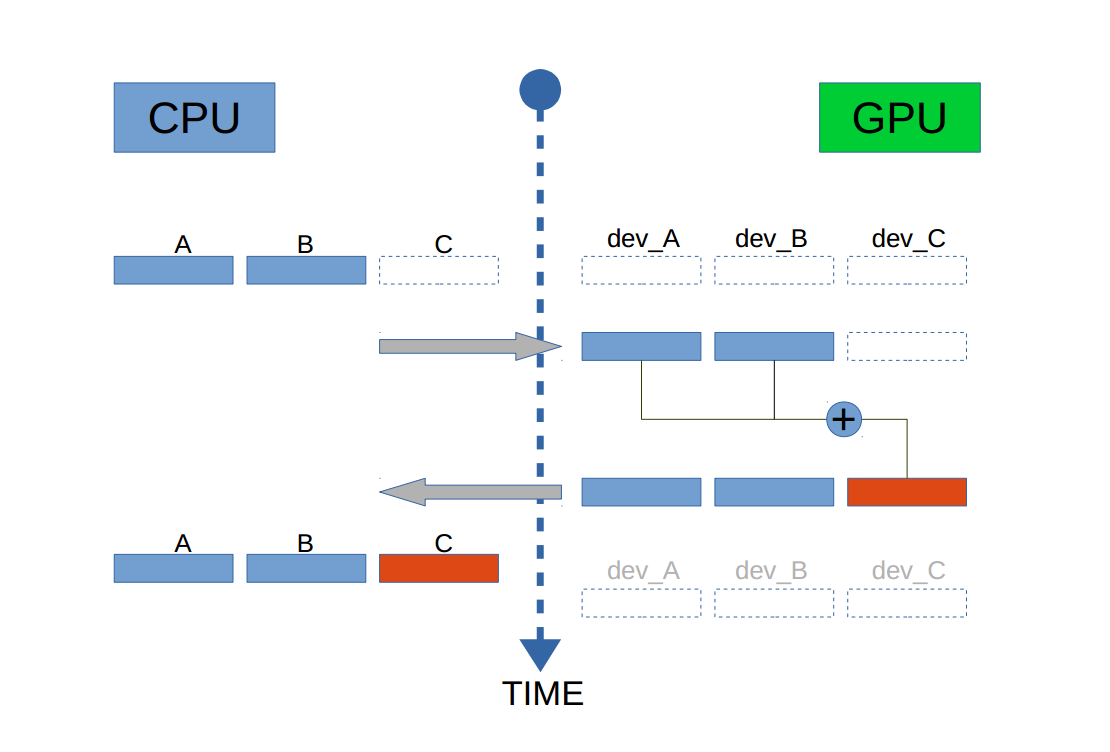
上述代码包含了CUDA代码的一般步骤:
1)声明所需指针在GPU,并且在GPU上开辟空间, 使用函数cudaMalloc()
2)从CPU拷贝所需内容到GPU的内存中,使用函数cudaMemcpy()
3)配置核函数,并执行操作。该函数在main函数之外,以__global__开头
4)把GPU上计算得到的结果拷贝回RAM,使用函数cudaMemcpy()
5)释放VRAM中的空间
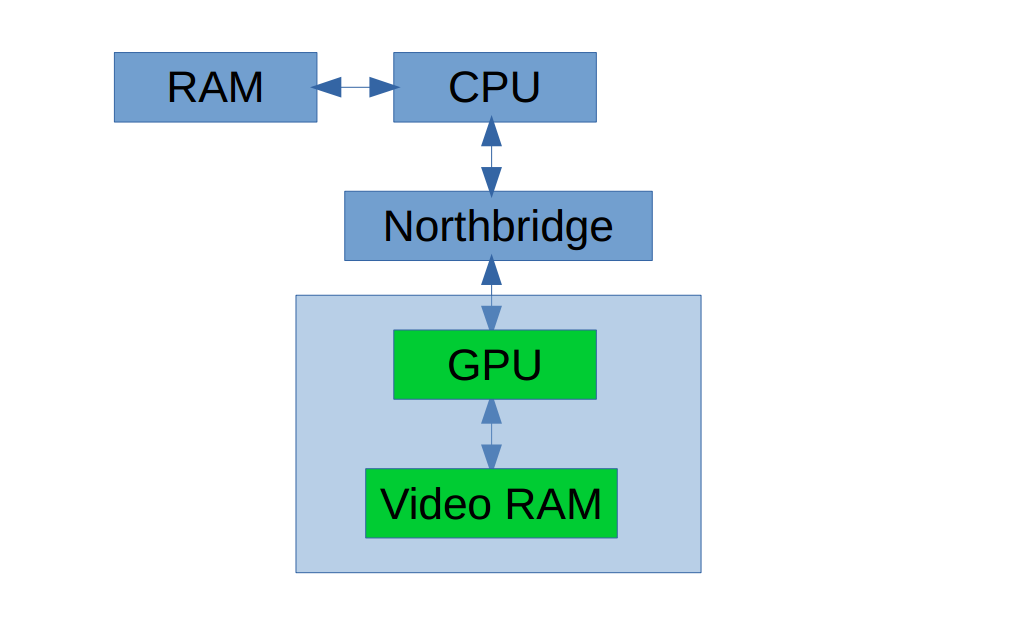
从两个维度理解CUDA基本概念物理概念 CUDA中的两个对象:Host,Device
Host 包括 CPU 和内存 DRAM
Device 包括 GPU 和存在与其上的存储 VRAM
VRAM 是 off-chip memory,即不在芯片上。由三部分组成:Global Memory,Texture Memory 和 Constant Memory。其中后二者为 read-only。
每个 GPU 芯片拥有一组不同的 memory,如上述。其中最重要的两个是 Global Memory 和 Shared Memory。
Host 和 Device 由北桥芯片连接:
对于CUDA编程,你需要负责以下内容:
1) 在 GPU memory 上开辟空间
使用GPU编程时,要从 MIMD(Multiple Instructions Multiple Data) 的思考形式转变到 SIMD(Single Instruction Multiple Data),在CUDA 中,每个核心执行的代码指令都是一样的,所以说是Single。
CUDA 提供的重要功能:组织线程,memory access。
与CUDA并行编程的代码分为两部分:
Host 部分代码由 ANSI C 来完成
Device 部分由 CUDA C 来完成,也对C++逐渐支持。
知道怎样组织 threads 在使用 CUDA 是十分重要的。
逻辑概念 在一个 grid 中所有的 thread 共享相同的 Global Memory。来自不同 block 的 threads 不能相互交流。即属于同一个 block 的 thread 可以相互交流。
threadIdx.x: 每个 block 中 x 方向 thread 的 id
threadIdx.y: 每个 block 中 y 方向 thread 的 id
threadIdx.z: 每个 block 中 z 方向 thread 的 id
blockIdx.x: 每个 block 的 x 方向上所含的 id
blockIdx.y: 每个 block 的 y 方向上所含的 id
blockIdx.z: 每个 block 的 z 方向上所含的 id
blockDim.x: 每个 block 的 x 方向上所含的 thread 数
blockDim.y: 每个 block 的 y 方向上所含的 thread 数
blockDim.z: 每个 block 的 z 方向上所含的 thread 数
gridDim.x: 每个 grid 的 x 方向上的 block 数
gridDim.y: 每个 grid 的 y 方向上的 block 数
gridDim.z: 每个 grid 的 z 方向上的 block 数
grids 和 blocks 使用 dim3 数据类型。 当给了数据的大小,如何决定 grid & block 的维度。
1)先决定 block 大小,即每个 block 由多少 threads,
2)然后根据数据大小和 block 大小,计算 grid dim。
为了得到 block dim,考虑两点:
1)kernel 的性能特点
2)GPU的物理极限
func<<<32, 1024>>>():
32:block 的数量为32个
1024:每一个 block 的 thread 数为1024个
为了配置 kernel 你需要知道:
1)kernel 的 thread 总数
2)这些 threads 的分布:block & grid 的维数,每个 block 由多少 threads
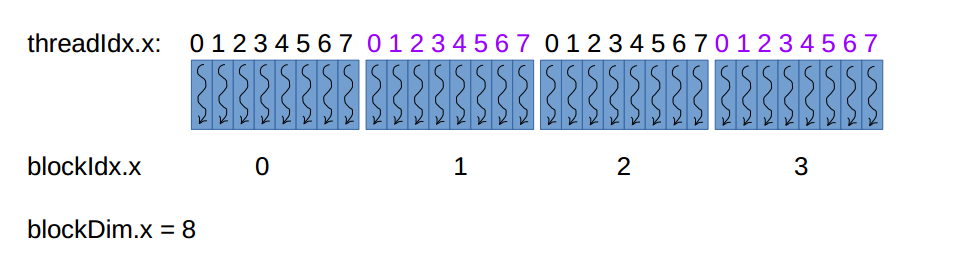
举例子:1D grid 1D block kernel func<<<4, 8>>>(),其 thread 分布是:
32个 threads 决定了会有32 份func()的拷贝,每一份由一个thread 执行,唯一不同的是每一个thread 的ID ,这样计算:idx=threadIdx.x + blockDim.x * blockIdx.x。0+8*1=8,最后一个thread的ID是7+8*3=31,所以,这个配置中的所有threads由唯一的ID:0~31。
再如:2D grid,2D block kernel:
1 2 3 dim3 threads (2 , 4 ) dim3 blocks (2 , 4 ) func<<<blocks, threads>>>
下图是所有相关的参数,及怎样得到每个 thread 的 ID:
其中每个矩形代表一个 block:blockDim.x=4,blockDim.y=2。每个 block 中的 thread 的组织是4行2列。
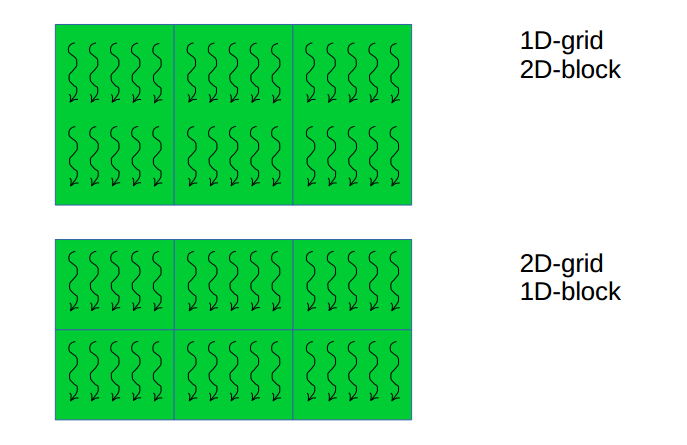
更多kernel的配置:
其中矩形表示一个block,相邻blocks组织成grid。
核心概念: