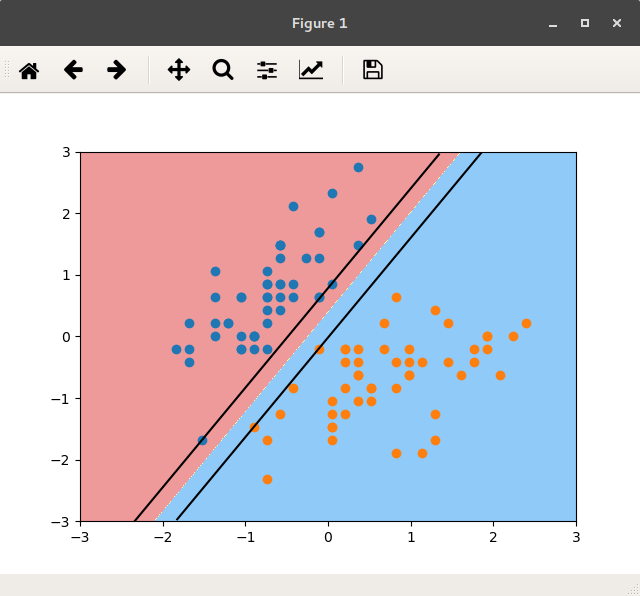
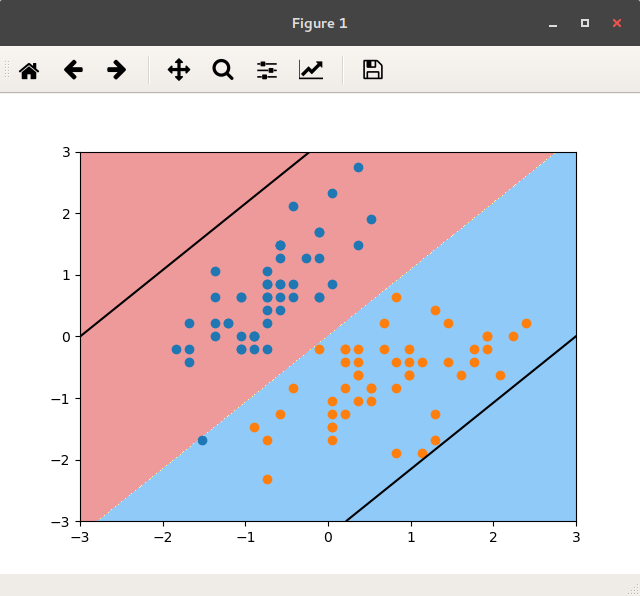
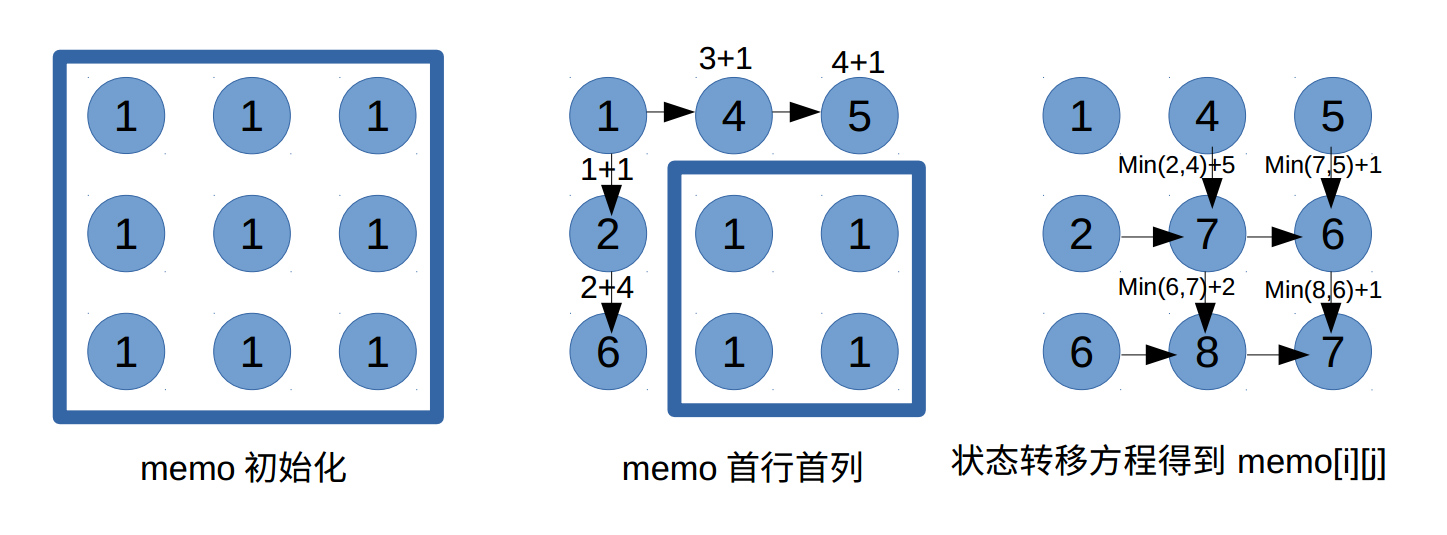
Given a m x n grid filled with non-negative numbers, find a path from **top left** to **bottom right** which minimizes the sum of all numbers along its path. Note: You can only move either *down* or *right* at any point in time.
Input: [ [1,3,1], [1,5,1], [4,2,1] ]
Output: 7 the path 1→3→1→1→1 minimizes the sum, which is 7.
stringgetLCS(conststring& s1, conststring& s2){ int m = s1.size(); int n = s2.size(); vector<vector<int>> memo(m ,vector<int>(n, 0)); // initilize memo for (int i=0; i<m; i++){ if (s1[i]==s2[0]){ for (int k=i; k<m; k++) memo[k][0] = 1; break; } }
for (int j=0; j<n; j++){ if (s2[j]==s1[0]){ for (int k=j; k<n; k++) memo[0][k]=1; break; } }
// DP progress for the rest for (int i=1; i<m; i++){ for (int j=1; j<n; j++){ if (s1[i]==s2[j]) memo[i][j] = 1 + memo[i-1][j-1]; else memo[i][j] = max(memo[i-1][j], memo[i][j-1]); } }
cout<<"The lenght of the LCS: "<<memo[m-1][n-1]<<endl; // get the longest common sequence string res = ""; while (m>=0 && n>=0){ if (s1[m] == s2[n]){ res = s1[m] + res; m--; n--; } elseif (m==0) n--; elseif (n==0) m--; else{ if (memo[m-1][n]>memo[m][n-1]) m--; else n--; } } return res; }
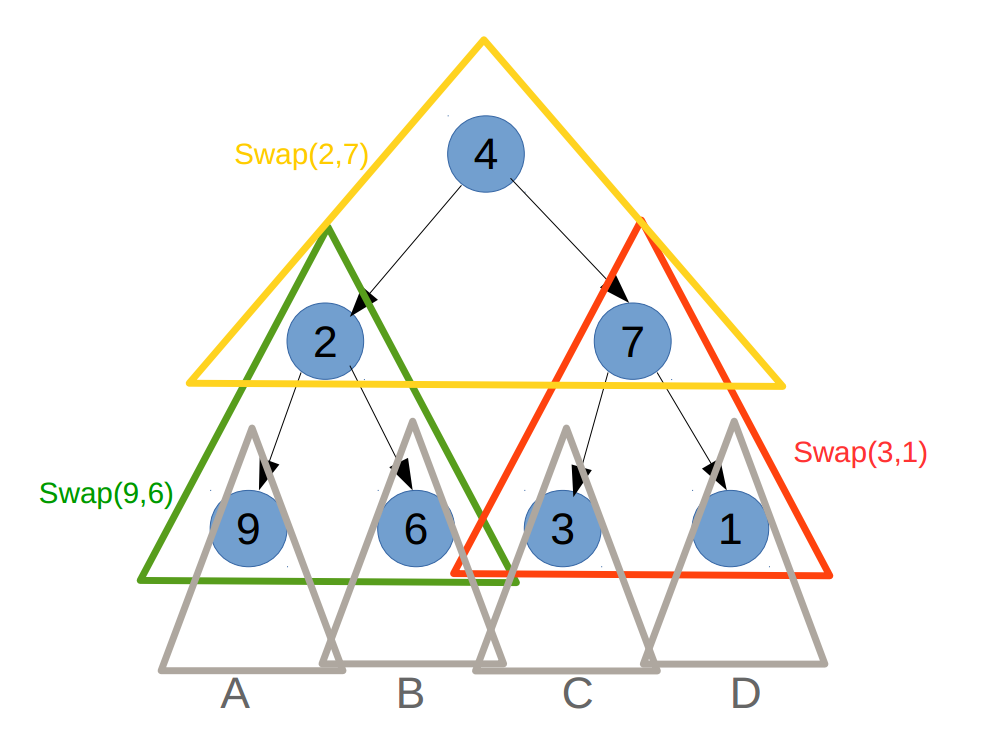
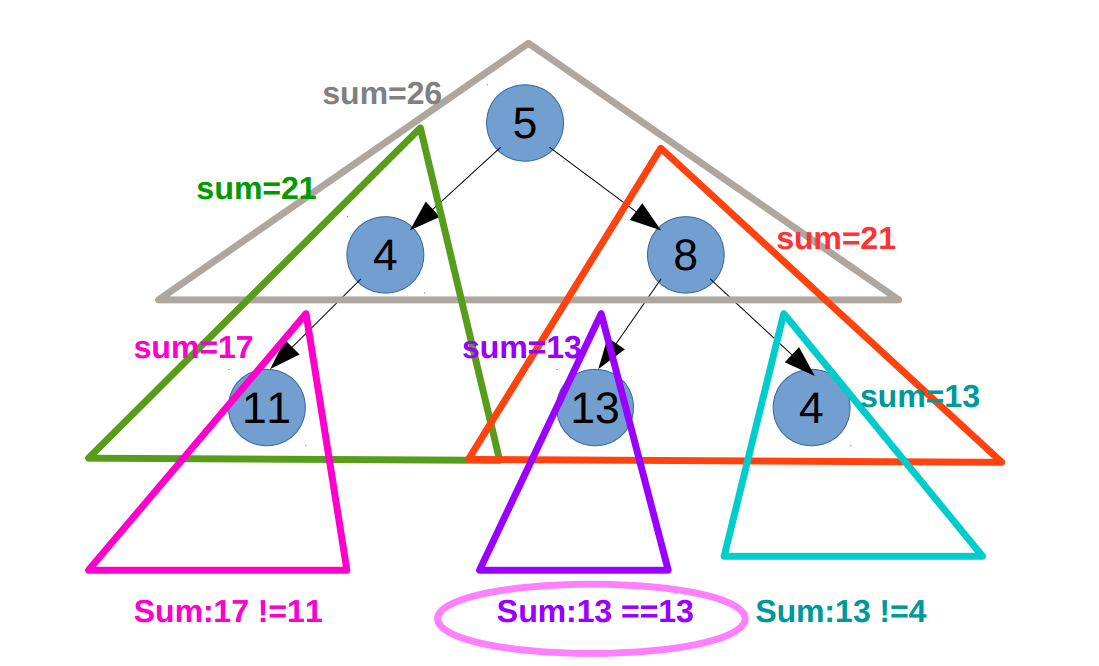
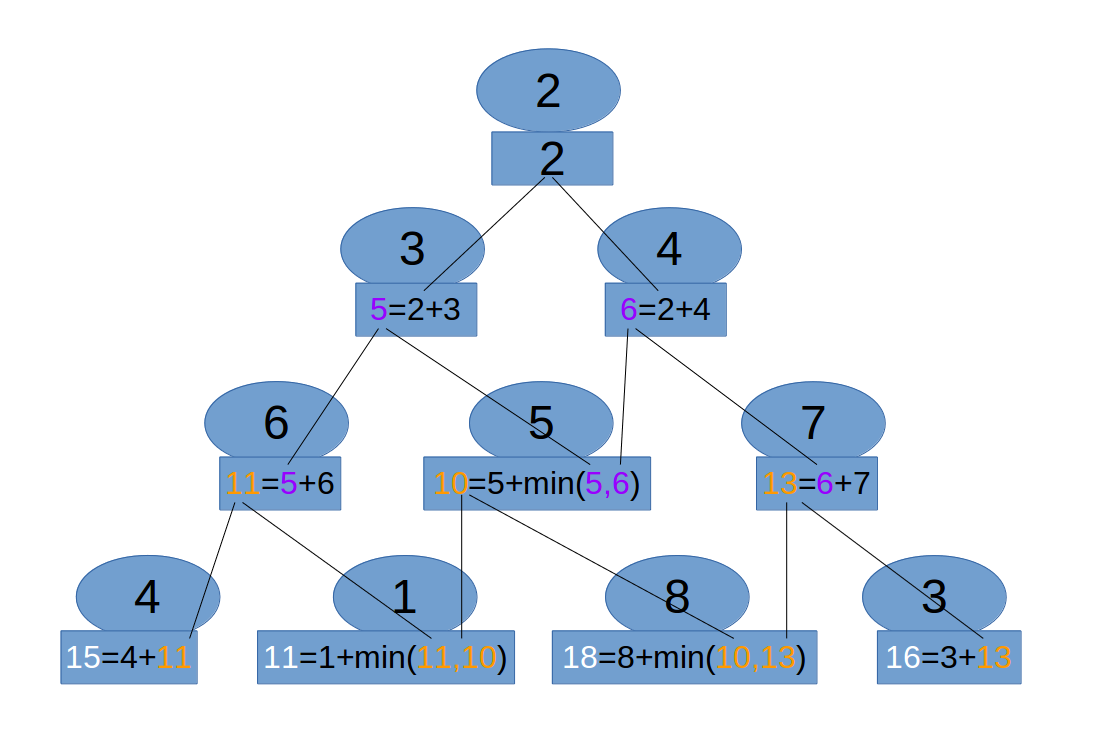
#120 Triangle
描述
1 2 3 4 5 6 7 8 9 10 11 12 13
Given a triangle, find the minimum path sum from top to bottom. Each step you may move to adjacent numbers on the row below.
For example, given the following triangle
[ [2], [3,4], [6,5,7], [4,1,8,3] ]
The minimum path sum from top to bottom is 11 (i.e., 2 + 3 + 5 + 1 = 11).
// 频繁操作只需求一次减法。效率高 intsumRange(int i, int j){ return memo[j+1] - memo[i]; } };
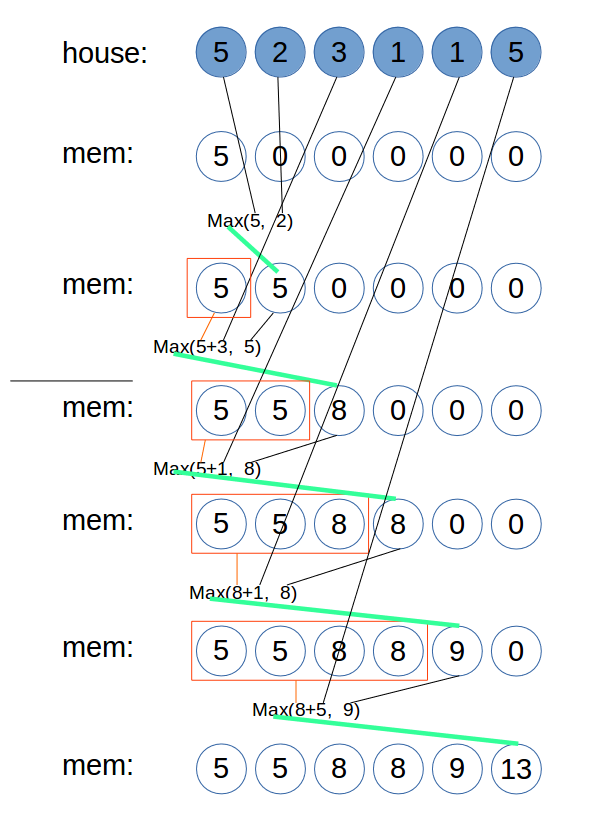
#198 House Robber
描述
1 2 3 4 5 6
一条街上有若干房子,现在要抢劫房子,从街头到街尾,所抢的房子不能直接相邻,求可能的最大收益。
Input: [2,7,9,3,1] Output: 12 Explanation: Rob house 1 (money = 2), rob house 3 (money = 9) and rob house 5 (money = 1). Total amount you can rob = 2 + 9 + 1 = 12.
with tf.Session() as sess: # init whole network sess.run(init_op) for i in range(num_train_steps): batch_inputs, batch_label = train_dataset.next_batch(hps.batch_size) # training: global_step+1 when sess.run() is called outputs_val = sess.run([loss, accuracy, train_op, global_step], feed_dict={ inputs: batch_inputs, outputs: batch_label, keep_prob: train_keep_prob }) # get three values from output_val loss_val, accuracy_val, _, global_step_val = outputs_val
# print for every 100 times if global_step_val % 20 == 0: print("step: %5d, loss: %3.3f, accuracy: %3.5f" % (global_step_val, loss_val, accuracy_val) )