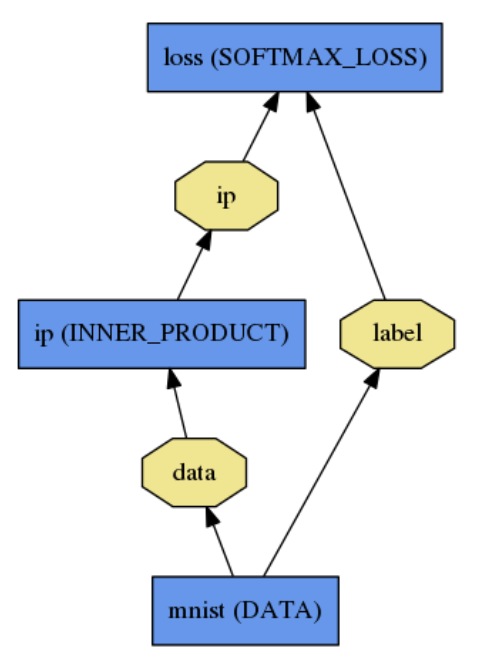
caffe中的每个层对象,都是一个模型的基本计算单元。一个层对象包括 “…filters, pool, take inner products, apply nonlinearities like rectified-linear and sigmoid and other elementwise transformations, normalize, load data, and compute losses like softmax and hinge”。见官方文档
backward():官方文档解释的很好:“given the gradient w.r.t. the top output, compute the gradient w.r.t. to the input and send to the bottom. A layer with parameters computes the gradient w.r.t. to its parameters and stores it internally.”。其中w.r.t.表示“with respect to”,中文表示“对…(求梯度等操作)”。这就是反向对参数求梯度的过程。当多个层链接到一起,就会形成反向传播的链条(对应了链式法则)。这个链式法则在Net::Backward()中实现
// 定义一个const访问指针,一个mutable访问指针 const Dtype* foo; Dtype* bar; // GPU上没有数据数据 foo = blob.gpu_data(); // data copied cpu->gpu. // 上下两句间没有任何操作,所以下一句并不会发生数据拷贝 foo = blob.cpu_data(); // no data copied since both have up-to-date contents. bar = blob.mutable_gpu_data(); // 一样,没有数据拷贝. // // 对数据进行操作... // bar = blob.mutable_gpu_data(); // 当前位于GPU上,没有数据拷贝到gpu. ?????? foo = blob.cpu_data(); // 因为数据被操作,所以数据拷贝从GPU到CPU发生。 foo = blob.gpu_data(); // 因为GPU和CPU都是最新数据,所以没有数据拷贝发生。
// ?????? bar = blob.mutable_cpu_data(); // still no data copied. bar = blob.mutable_gpu_data(); // data copied cpu->gpu. bar = blob.mutable_cpu_data(); // data copied gpu->cpu.
The following packages have unmet dependencies: libxml2-dev : Depends: libxml2 (= 2.7.8.dfsg-5.1ubuntu4) but 2.7.8.dfsg-5.1ubuntu4.6 is to be installed
junhui@gnome:~/caffe$ sudo make pytest –j4 CXX/LD -o python/caffe/_caffe.so python/caffe/_caffe.cpp python/caffe/_caffe.cpp:10:31: fatal error: numpy/arrayobject.h: No such file or directory #include <numpy/arrayobject.h> ^ compilation terminated. Makefile:517: recipe for target 'python/caffe/_caffe.so' failed make: *** [python/caffe/_caffe.so] Error 1
解决方法:
在Makefile.config文件中的这个地方:
1 2 3
# We need to be able to find Python.h and numpy/arrayobject.h. PYTHON_INCLUDE := /usr/include/python2.7 \ /usr/lib/python2.7/dist-packages/numpy/core/include
添加一行:
1 2 3 4
# We need to be able to find Python.h and numpy/arrayobject.h. PYTHON_INCLUDE := /usr/include/python2.7 \ /usr/lib/python2.7/dist-packages/numpy/core/include \ /usr/local/lib/python2.7/dist-packages/numpy/core/include
CXX .build_release/src/caffe/proto/caffe.pb.cc In file included from .build_release/src/caffe/proto/caffe.pb.cc:5:0: .build_release/src/caffe/proto/caffe.pb.h:12:2: error: #error This file was generated by a newer version of protoc which is #error This file was generated by a newer version of protoc which is ^ .build_release/src/caffe/proto/caffe.pb.h:13:2: error: #error incompatible with your Protocol Buffer headers. Please update #error incompatible with your Protocol Buffer headers. Please update ^ .build_release/src/caffe/proto/caffe.pb.h:14:2: error: #error your headers. #error your headers. ^ In file included from .build_release/src/caffe/proto/caffe.pb.cc:5:0: .build_release/src/caffe/proto/caffe.pb.h:26:55: fatal error: google/protobuf/generated_enum_reflection.h: No such file or directory #include <google/protobuf/generated_enum_reflection.h>
__global__ voidConvolution(float* N, float* P, int N_size){ __shared__ float N_ds[TILE_SIZE + KERNEL_LENGTH-1]; int tid = threadIdx.x + blockDim.x * blockIdx.x; int n = KERNEL_LENGTH/2;
Input: "(()())(())" Ouput: "()()()" Explanation: The input string is "(()())(())", with primitive decomposition "(()())" + "(())". After removing outer parentheses of each part, this is "()()" + "()" = "()()()".