__global__ voidhisto_kernel( char *buffer, long size, int *histo ){ int i = threadIdx.x + blockIdx.x * blockDim.x; int stride = blockDim.x * gridDim.x; // stride loop while (i < size) { atomicAdd( &(histo[buffer[i]]), 1 ); i += stride; } }
其中atomicAdd( &(histo[buffer[i]]), 1 )展示了如何使用原子操作:atomicAdd( add, y ), 这个操作读取地址add中值,将y加到add的值上。这个例子中add就是直方图中相应元素的位置。
int i = threadIdx.x + blockIdx.x * blockDim.x; int offset = blockDim.x * gridDim.x; // 第一段计算 while (i < size) { atomicAdd( &temp[buffer[i]], 1 ); i += offset; } __syncthreads();
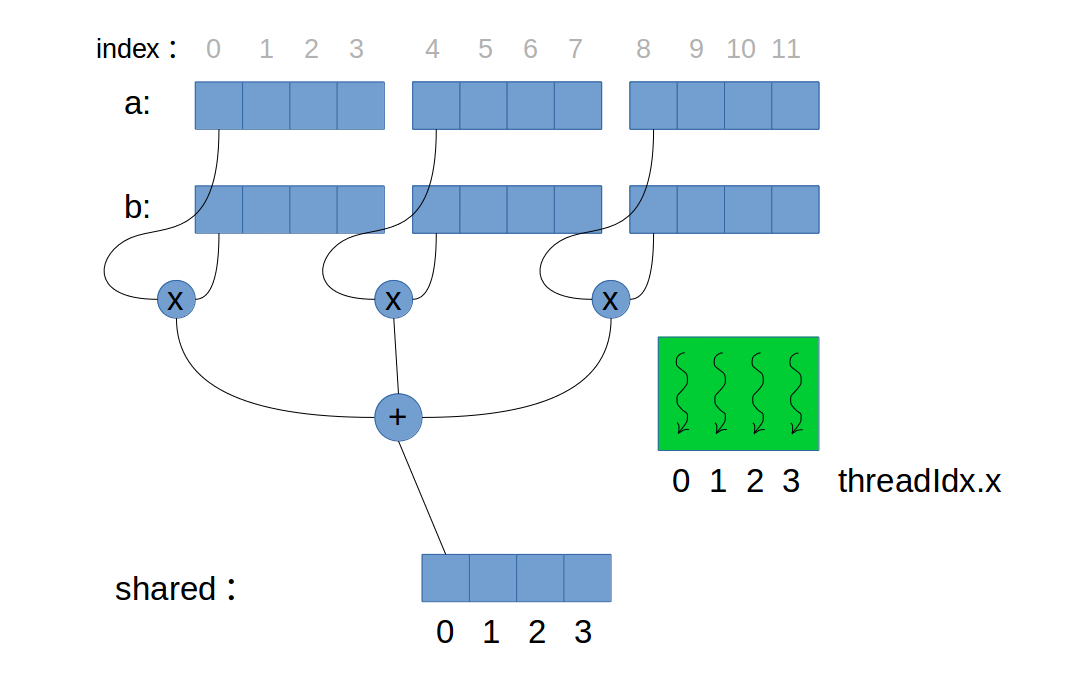
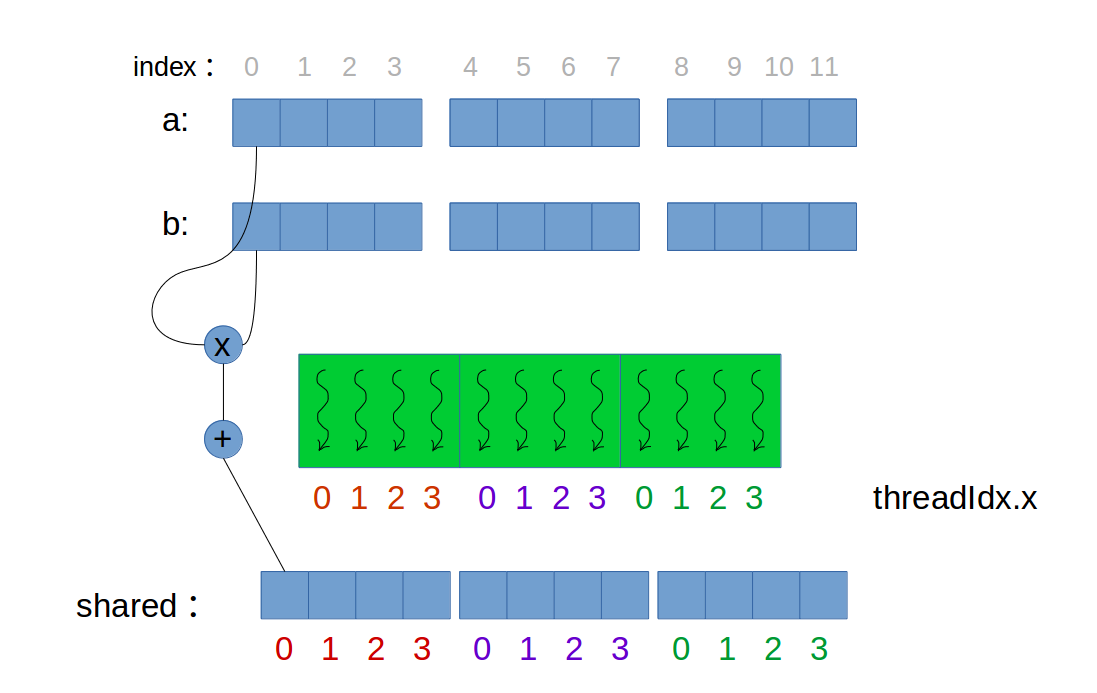
// thread的行ID和列ID int row = threadIdx.y; int col = threadIdx.x;
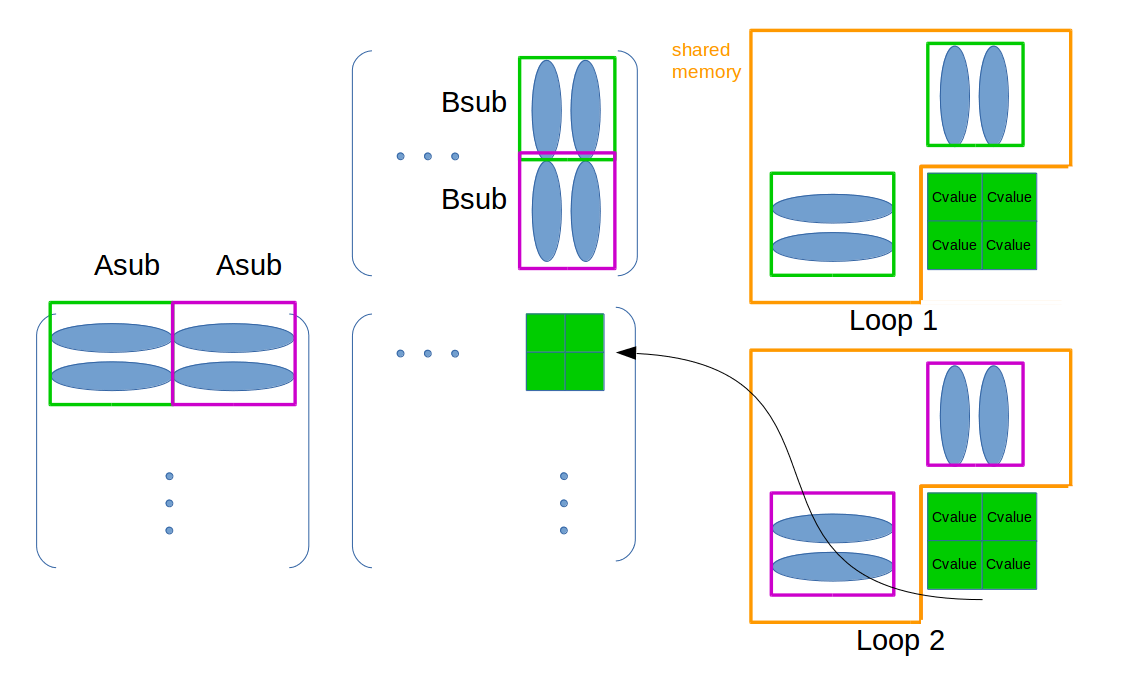
// Loop over all the sub-matrices of A and B that are // required to compute Csub // Multiply each pair of sub-matrices together // and accumulate the results to Cvalue for (int m = 0; m < (A.width / BLOCK_SIZE); ++m) {
// 得到这个block在这次循环中的A的子矩阵 Matrix Asub = GetSubMatrix(A, blockRow, m);
// 得到这个block在这次循环中的B的子矩阵 Matrix Bsub = GetSubMatrix(B, m, blockCol);
// 计算当前A的子矩阵与B的子矩阵,相乘后累加结果。 // 当外层循环结束,表示累加每一块累加的结果完成, // 得到最后的C中这个位置的结果。 for (int e = 0; e < BLOCK_SIZE; ++e) Cvalue += As[row][e] * Bs[e][col];
// Synchronize to make sure that the preceding // computation is done before loading two new // sub-matrices of A and B in the next iteration // 等待这一阶段的 加类乘完成后,才能够进行下一次循环,更新shared memory中的内容。 __syncthreads(); }
// Write Csub to device memory // Each thread writes one element SetElement(Csub, row, col, Cvalue); }