GPU系统中的各种内存数量约束了整个系统中的block数量和threads数量。每个thread使用各种存储的多少影响着可以使用threads的数量。
SM资源分割:
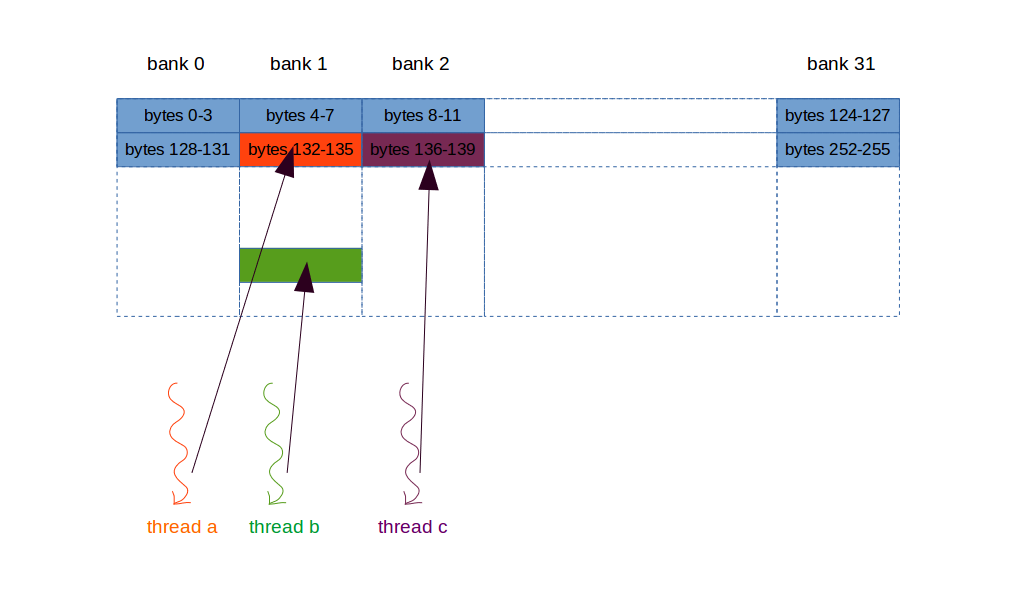
GPU的计算资源以SM为单位,SM之间共享global memory,不过通常global memory足够大,所以每个thread不管使用多少global memory,对可调用的threads数量几乎没有影响(本来设计kernel的原则之一就是最少的使用Global memory)。
增加资源占量后(thread占用Registers的数量或block占用Shared memory的数量)导致并行性急剧下降,例如,增加每个thread的register数量,可以并行的block数量就可能大幅度下降(下降是以一个block为单位下降的)。使用CUDA Occupancy Calculator工具可以修改某一资源的数值,得到其他资源的相应变化。
一个
SM中的Registers数量是有限的这些寄存器要被划分给这个SM中的所有threads。所以如果每个thread使用的寄存器过多时,这个SM中实际使用的threads数会减少,使得资源(应用程序对GPU处理单元)占用率下降。
比如一个SM中有768个threads,含有8k个registers。要想最大并行化(最大化占用率),即使用所有的threads,那么就要保证每个thread分配最多10个registers,这种情况下共使用
10x768=7680个registers,没有超过8k个。但是如果每个threads分配11个registers,此时
11x768=8448个registers,此时算数上最多只能使用727个threads(8000/11=727.27),实际情况会比727还要少,因为超出限制后,threads数的减少是以block为粒度的减少:如果一个block有256个threads,那么可用threads数就不是从768减少到727,而是从768减少到512,只要threads数减少,就以block为单位(粒度)地减少。如果要减少threads超过256(一个block的threads数),如257,那么实际就要减少2个block(256+1,2个blocks)。分析一个资源分配的例子:一个SM有
768个threads,8000个registers。如果每个threads使用11个registers,并且每个block含有256个threads。(上面计算过:最大并行化的register的分配是每个thread使用10个registers。)一个SM驻扎的threads个数有多少
可用threads个数:
8000/11=727个threads,而且2x256=512,3x256=768超过了727,所以这个SM驻扎2个blocks(512threads,与上述相符合)。一个SM驻扎的warp数量有多少
2个blocks共有512个threads,所以512/32=16个warps,这个SM驻扎16个warps。而理论极限是驻扎768/32=24个warps。16远小于24.warp数量减少意味着什么
通过上述计算,没有合理分配registers的结果是,存在资源的浪费,不能最大并行化。
同样的,一个
SM中的shared memory的大小也是有限的回忆:在同一个
block的threads共享同一块shared memory。一个SM中实际使用的block数量也是与每个block被分配的shared memory的大小有关。
比如:一个SM有
8个blocks,可使用shared memory为16kB。所以想要充分使用所有的blocks,每个block被分配shared memory最多为2kB(16kB/8). 换句话说,为了最大并行化,充分使用SM的计算资源,这个SM中每个block可使用的shared memory最多为2kB。假如,每个block使用了
4kB,则实际只是用了4个(16kB/4kB)blocks,相较于上一种中情况只是用了一半的threads。假如,每个block使用
5kB,则实际只用了3个(16kB/5kB)blocks,此种情况可使用的threads就更少了。
回忆实战中,有一回,对kernel的配置没有超过硬件极限,但是实际上每个block只能使用256个threads,超过256,程序就不会得到正确结果。当时不清楚为什么,通过这篇笔记,可以解释了。是因为每个threads使用了过多的Registers(当时程序中没有使用Shared memory)的原因。导致可用threads数减少。
敲黑板Registers数量和每个block分配到的shared memory的大小,共同约束了整个系统中的block数量个threads数量。实际应用中也要尽量少的使用存储资源,从而最大化并行程度。内存是竞争资源