594, 349, 350, 1, 290, 205, 451, 202,
map包括有序map和无序map,set也分为有序set和无序set。
map由键值构成,set中元素无重复。
常用操作: find(), insert(), erase(), change(), search(),
#594 最长Harmonius 子序列
描述
1
2
3Input: [1,3,2,2,5,2,3,7]
Output: 5
Explanation: The longest harmonious subsequence is [3,2,2,2,3].思路:
1) 第一步 将数组元素作为key,对应出现的次数作为val,放入map中。如下:map | 1st | 2nd | 3rd | 4th| 5th -|-|-|-|-|- key | 1 | 2 | 3 | 5 | 7 | val | 1 | 3 | 2 | 1 | 1 |2) 遍历map:
对于key=1,如果key=2存在,则子序列长度为: key=1的val + key=2的val: 1+3=4 对于key=2,如果key=3存在,则子序列长度为: key=2的val + key=3的val: 3+2=5 对于key=3,如果key=4不存在,continue 对于key=5,如果key=6不存在,continue 对于key=7,如果key=8不存在,continue 最终返回最大值 5实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int findLHS(vector<int>& nums) {
// create map
map<int, int> mp;
for (auto& item: nums)
mp[item]++;
// main process
int res = 0;
for (auto itr = mp.begin(); itr!=mp.end(); itr++){
if ( mp.find(itr->first + 1) != mp.end()){
res = max(res, mp[itr->first] + mp[itr->first+1]); // update max
}
}
return res;
}
#349 Intersection Of Two Arrays
描述
1
2Input: nums1 = [4,9,5], nums2 = [9,4,9,8,4]
Output: [9,4]逻辑
第一步:将nums1中元素放入set中 第二步:从set中查找nums2中每个元素, 如果找到,就放入结果set中,如此一来,结果中也没有重复元素。 如果没找到,continue。实现
1
2
3
4
5
6
7
8
9
10
11
12vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
// 第一步
set<int> record(nums1.begin(), nums1.end());
set<int> resSet;
// 第二步
for (int i=0; i<nums2.size(); i++)
if (record.find(nums2[i]) != record.end()) //in record
resSet.insert(nums2[i]);
return vector<int>( resSet.begin(), resSet.end() );
}
#350 INtersection Of Two Arrays II
描述
1
2Input: nums1 = [1,2,2,1], nums2 = [2,2]
Output: [2,2]逻辑
第一步:将nums1中元素放入map中 第二步:遍历num2中每个元素: 如果当前元素在map中的频数>0, 那么在结果vector中加入这个元素,同时map中这个元素的频数-1. 如果当前元素在map中的频数==0,说明这个元素不是共有的,continue。实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
// 第一步
map<int, int> record;
for (int i=0; i<nums1.size(); i++)
record[nums1[i]] ++;
// 第二步
vector<int> resV;
for (int i=0;i<nums2.size(); i++){
if (record[nums2[i]] > 0){
resV.push_back(nums2[i]);
record[nums2[i]] -- ;
}
}
return resV;
}
#1 Two Sum
描述
1
2
3
4
5
6
7Given nums = [2, 7, 11, 15], target = 9,
Because nums[0] + nums[1] = 2 + 7 = 9,
return [0, 1].
NOTE:You may assume that each input would have exactly one solution,
and you may not use the same element twice.逻辑
遍历nums中所有元素nums[i]: 如果:map中没有找到target-nums[i]这个值,就把{nums[i], i}放入map中; 如果:map中找到了target-nums[i],那么当前值index和target-nums[i]的index放入结果中。done实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14vector<int> twoSum(vector<int>& nums, int target){
std::unordered_map<int, int> record;
for (int i=0;i<nums.size();i++){
// nums[i] is not in the record
if (record.find(target - nums[i]) == record.end()){
record[nums[i]] = i;
}
else {// nums[i] is in the record
int res[2] = {record[target-nums[i]], i};
return vector<int>(res, res+2);
}
}
throw invalid_argument("NO SOLUTION!");
}敲黑板这个问题虽然简单,但有两点值得注意:
元素逐个放入map,map的value为index。相同的技巧,看#290.
#290 Word Pattern
描述
1
2Input: pattern = "abba", str = "dog cat cat dog"
Output: true逻辑 (不容易想到)
要使用c++ 中 map容器的一个性质:”空的map中任何key对应的value都是0”。
第一步:为两个input分别声明map。 第二步:同步遍历pattern和str每一个元素: 如果 两个map的key对应的value(index)相同,赋值给两个value为index+1; 否则 返回false 最终判断:最终的循环变量i是否等于input 的长度。
实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15bool wordPattern(string pattern, string str) {
map<char, int> mp1;
map<string, int> mp2;
// 从一个string中逐个读取单词
istringstream in(str);
int i = 0, n = pattern.size();
for (string word; in >> word; ++i) {
if (i == n || mp1[pattern[i]] != mp2[word])
return false;
mp2[word] = i + 1;
mp1[pattern[i]] = i + 1;
}
return i == n;
}
细节:从一个string中逐个读取单词。使用了c++中map的特性,考虑其他更通用的方法。
#205 Isomorphic Strings
描述
1
2
3
4
5Input: s = "egg", t = "add"
Output: true
Input: s = "foo", t = "bar"
Output: false思路
思路与#290相同。用图示表示出来:
以 s = “egg”, t = “add” 为例:
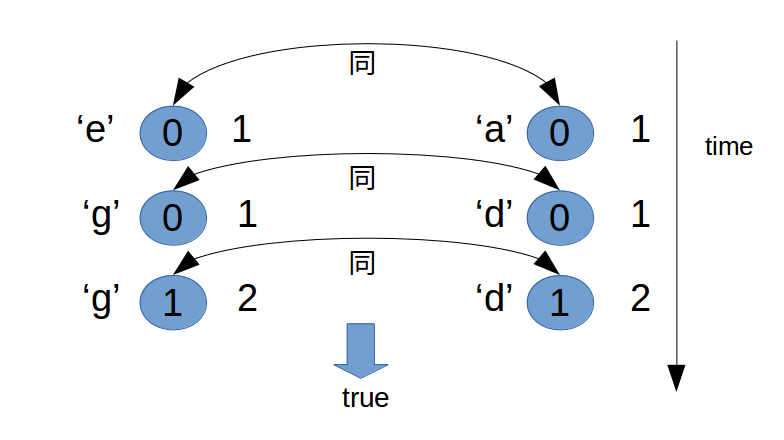
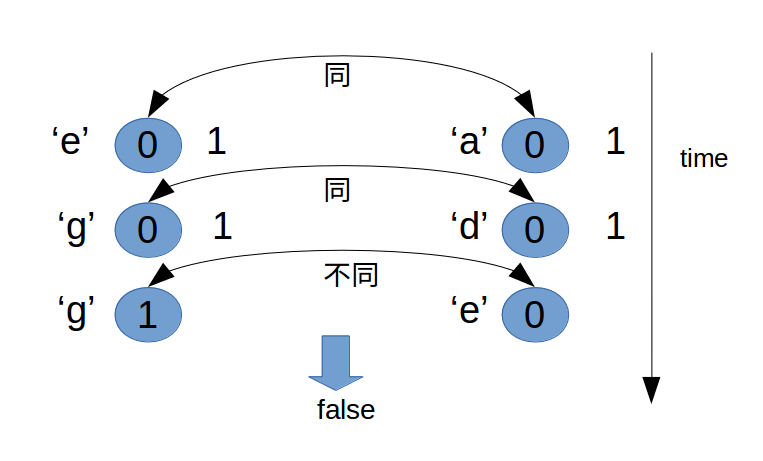
以 s = “egg”, t = “ade” 为例:
实现
1
2
3
4
5
6
7
8
9
10
11
12bool isIsomorphic(string s, string t) {
unordered_map<char, int> mpS;
unordered_map<char, int> mpT;
for (int i=0; i<s.size(); i++){
if (mpS[s[i]] != mpT[t[i]])
return false;
mpS[s[i]]=i+1;
mpT[t[i]]=i+1;
}
return true;
}
敲黑板逐个放入map
#451 Sort Charactors By Frequency
描述
1
2
3
4
5Input:
"aBbbccc"
Output:
"cccbbaB"逻辑
很直接
第一步:将string s中元素放入map中,并且把键值对作为元素翻入vector中。 第二步:按value的大小从大到小排序。 第三步:将vector中的元素放入结果string中。实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25struct cmpByValue {
bool operator()(const pair<char, int>& l, const pair<char, int>& r){
return l.second > r.second;
}
};
string frequencySort(string s) {
string res;
// 第一步
unordered_map<char, int> mp;
for (int i=0; i<s.length(); i++)
mp[s[i]] ++;
// 第二步
vector<pair<char, int>> mapValue(mp.begin(), mp.end());
sort(mapValue.begin(), mapValue.end(), cmpByValue());
// 第三步
for (int i=0; i<mapValue.size(); i++){
for (int j=0; j<mapValue[i].second; j++){
res+=mapValue[i].first;
}
}
return res;
}
#202 Happy Number
描述
1
2
3
4
5
6
7
8
9Input: 19
Output: true
Explanation:
1**2 + 9**2 = 82
8**2 + 2**2 = 68
6**2 + 8**2 = 100
1**2 + 0**2 + 0**2 = 1
Those numbers for which this process ends 1 are happy numbers.逻辑
过程如描述中的Explanation。要注意的是,对于不是happy number的数,防止无限循环,将每一步的结果放入set中(不重复)。
实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21int func(int n){
int res = 0;
while(n!=0){
res+=pow(n % 10,2);
n/=10; // 每次循环,从高高位到低位得到每一位的数值。
}
return res;
}
bool isHappy(int n) {
unordered_set<int> record;
while (1){
if (n ==1) return true;
record.insert(n);
n = func(n);
if (record.find(n) != record.end())
return false;
}
}